NGBoost#
Case 1: 線形データ・不均一分散#
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import norm
x = np.linspace(0, 10, 1000)
sigma = np.sqrt(x)
y = norm.rvs(loc=x, scale=sigma, random_state=0)
X = x.reshape(-1, 1)
fig, ax = plt.subplots()
ax.scatter(x, y)
ax.plot(x, x, color="black", alpha=.5, label="mean")
ax.set(xlabel="x", ylabel="y")
ax.legend()
fig.show()

from ngboost import NGBRegressor
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
ngb = NGBRegressor().fit(X_train, y_train)
y_pred = ngb.predict(X_test)
y_dist = ngb.pred_dist(X_test)
print('Test MSE', mean_squared_error(y_pred, y_test))
# test Negative Log Likelihood
test_NLL = -y_dist.logpdf(y_test).mean()
print('Test NLL', test_NLL)
[iter 0] loss=2.7086 val_loss=0.0000 scale=1.0000 norm=3.0713
[iter 100] loss=2.1882 val_loss=0.0000 scale=2.0000 norm=3.5628
[iter 200] loss=1.9961 val_loss=0.0000 scale=2.0000 norm=3.3157
[iter 300] loss=1.9229 val_loss=0.0000 scale=2.0000 norm=3.2333
[iter 400] loss=1.8813 val_loss=0.0000 scale=2.0000 norm=3.1700
Test MSE 5.000888211626713
Test NLL 2.1957447284363765
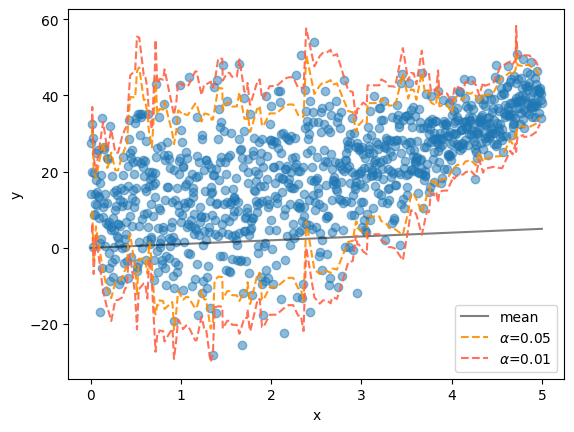
fig, ax = plt.subplots()
ax.scatter(x, y, alpha=.5)
ax.plot(x, x, color="black", alpha=.5, label="mean")
ax.set(xlabel="x", ylabel="y")
ax.legend()
X_test = np.sort(X_test, axis=0)
y_dist = ngb.pred_dist(X_test)
alphas = [0.05, 0.01]
colors = ["darkorange", "tomato"]
for alpha, color in zip(alphas, colors):
upper = norm.ppf(q=1 - (alpha/2), loc=y_dist.params["loc"], scale=y_dist.params["scale"])
lower = norm.ppf(q=(alpha/2), loc=y_dist.params["loc"], scale=y_dist.params["scale"])
ax.plot(X_test[:, 0], upper, alpha=.9, color=color, linestyle="--", label=rf"$\alpha$={alpha}")
ax.plot(X_test[:, 0], lower, alpha=.9, color=color, linestyle="--")
ax.legend()
fig.show()
Case 2: 非線形データ・不均一分散#
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import norm
x = np.linspace(0, 5, 1000)
sigma = (np.sin(x / 1) + 2) * 5
z = 10 + x + x ** 2
y = norm.rvs(loc=z, scale=sigma, random_state=0)
X = x.reshape(-1, 1)
fig, ax = plt.subplots()
ax.scatter(x, y)
ax.plot(x, z, color="black", alpha=.5, label="mean")
ax.set(xlabel="x", ylabel="y")
ax.legend()
fig.show()

from ngboost import NGBRegressor
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
ngb = NGBRegressor().fit(X_train, y_train)
y_pred = ngb.predict(X_test)
y_dist = ngb.pred_dist(X_test)
print('Test MSE', mean_squared_error(y_pred, y_test))
# test Negative Log Likelihood
test_NLL = -y_dist.logpdf(y_test).mean()
print('Test NLL', test_NLL)
[iter 0] loss=4.0958 val_loss=0.0000 scale=1.0000 norm=11.9310
[iter 100] loss=3.7532 val_loss=0.0000 scale=2.0000 norm=16.8669
[iter 200] loss=3.6163 val_loss=0.0000 scale=2.0000 norm=15.8977
[iter 300] loss=3.5650 val_loss=0.0000 scale=2.0000 norm=15.4377
[iter 400] loss=3.5322 val_loss=0.0000 scale=1.0000 norm=7.5611
Test MSE 124.64039627780312
Test NLL 3.8217800901164596
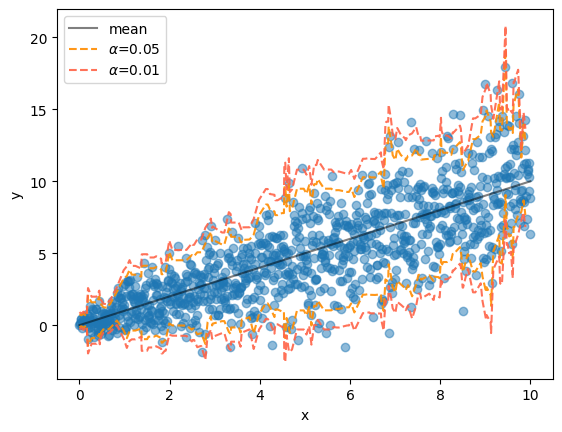
fig, ax = plt.subplots()
ax.scatter(x, y, alpha=.5)
ax.plot(x, x, color="black", alpha=.5, label="mean")
ax.set(xlabel="x", ylabel="y")
ax.legend()
X_test = np.sort(X_test, axis=0)
y_dist = ngb.pred_dist(X_test)
alphas = [0.05, 0.01]
colors = ["darkorange", "tomato"]
for alpha, color in zip(alphas, colors):
upper = norm.ppf(q=1 - (alpha/2), loc=y_dist.params["loc"], scale=y_dist.params["scale"])
lower = norm.ppf(q=(alpha/2), loc=y_dist.params["loc"], scale=y_dist.params["scale"])
ax.plot(X_test[:, 0], upper, alpha=.9, color=color, linestyle="--", label=rf"$\alpha$={alpha}")
ax.plot(X_test[:, 0], lower, alpha=.9, color=color, linestyle="--")
ax.legend()
fig.show()