ロジスティック回帰#
モデル#
目的変数\(y\in\{0,1\}\)の二値分類において、\(y=1\)である確率を\(p\)、\(y=0\)である確率を\(1-p\)とする。
ロジスティック回帰(logistic regression) は\(y=1\)の確率を表現するモデル
である。ここで \(\frac{1}{1 + \exp(-z)}\) は \((-\infty, \infty)\) の入力を \((0, 1)\)の範囲にする関数で、 (ロジスティック)シグモイド関数 という。
また、ロジスティック回帰はオッズ比の対数を線形モデルで説明するモデル
ともいえる。
モデル表現の導出#
の両辺の指数をとると
となり、
であるため、2つのモデル表現が同値である。
前半部の導出
両辺を\(p\)で割ると
後半部の導出
については、分子・分母に\(\exp(z)\)を掛けると
であり、分母部分 \((1 + \exp(z)) /\exp(z)\) については
となる。
※\(\frac{ 1 }{ \exp(z) } = \exp(-z)\)については、 \(\frac{ 1 }{ \exp(z) }\) は \(\exp(z)\) と乗じると \(1\) になるため、指数法則 \(e^{n} \cdot e^{m} = e^{nm}\) より、 \(\exp(-z)\) となる
誤差関数#
ロジスティック回帰は、統計学的な言い方だと最尤推定法でパラメータを推定する。
機械学習的な言い方をすると交差エントロピー誤差を最小化するようにパラメータを推定する。
ベルヌーイ分布#
ロジスティック回帰は\(P(y=1) = p, P(y = 0) = 1-p\)のベルヌーイ分布に従う。
この確率質量関数は一括で書くと
と書くことができる。
尤度関数#
尤度関数\(L(\theta)\)とは一般に確率(密度/質量)関数\(f(x| \theta)\)の積
である(独立に得られたサンプルを仮定するので単純な積が同時確率を意味する)。
そのため、ベルヌーイ分布の尤度関数は
となる。
ロジスティック回帰で使う場合、\(p \in [0, 1]\)はロジスティック回帰の予測値\(p_i=\sigma(\beta^\top x_i)\)、\(y \in \{0, 1\}\)は実測値である。
確率の積だとすごく小さい値になって計算が大変なので、通常は対数を取った対数尤度を使う。
交差エントロピー誤差#
ベルヌーイ分布の対数尤度関数の符号を負に反転させたものを交差エントロピー誤差(cross entropy loss)という。log lossやlogistic lossとも呼ばれる
単に言葉の問題だが、統計学系の分野では「対数尤度の最大化(最尤推定法)」という言い方をして、機械学習では「交差エントロピー誤差(=負の対数尤度)の最小化」とか言う。やってることは同じ。
スクラッチ実装例#
# 対数尤度
import numpy as np
def sigmoid(x):
return 1 / (1 + np.exp(-x))
def log_likelihood(X, y, beta):
p = sigmoid(X @ beta)
c = 0.0001
p = np.clip(p, a_min=c, a_max=1 - c) # log(p), log(1-p)でゼロをいれないようにする
return np.sum(y * np.log(p) + (1 - y) * np.log(1 - p))
2次元の特徴量からなる、次のようなデータがあるとする
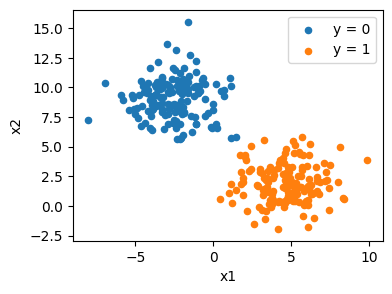
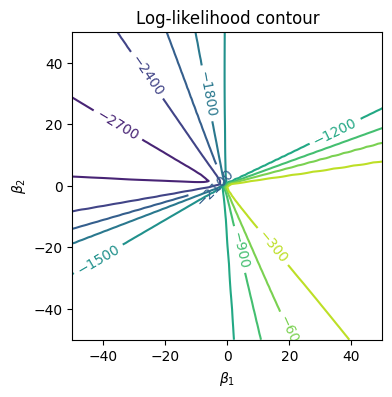
さまざまな\(\beta_1, \beta_2\)の値のもとでの対数尤度を計算すると次のような等高線になる
/tmp/ipykernel_6042/1805774186.py:5: RuntimeWarning: overflow encountered in exp
return 1 / (1 + np.exp(-x))
from scipy.optimize import minimize
beta0 = np.zeros(X.shape[1])
res = minimize(
fun=lambda beta: -log_likelihood(X, y, beta), # minimizeの関数なので負にする
x0=beta0,
method="BFGS",
options={"gtol": 1e-6, "maxiter": 1000},
)
beta_hat = res.x
print("success:", res.success)
print("message:", res.message)
print("beta_hat:", beta_hat)
print("max loglik:", -res.fun)
success: True
message: Optimization terminated successfully.
beta_hat: [ 41.07346687 -13.25167556]
max loglik: -0.0300015001000042
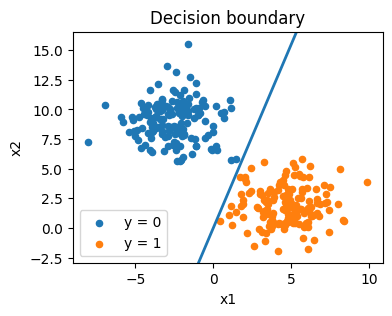
推定値での識別境界は次のようになる
勾配#
交差エントロピーの勾配は
導出
総和を取るまえの1レコード単位のものを使う。
\(\s\)に関する微分
より、
(参考)使った微分
from sklearn.datasets import load_breast_cancer
X, y = load_breast_cancer(return_X_y=True)
\(y \in \{-1, 1\}\)にする場合#
上記の例では\(y \in \{0, 1\}\)としていた。\(y\in \{-1, 1\}\)とする場合は少し書き方が変わる
\(y=1\)の確率と\(y=-1\)の確率がそれぞれ
で表されるとする。\(y\in \{-1, 1\}\)のとき、これらを1つにまとめて、\(y\)の確率を
と書くことができる。
尤度は
負の対数尤度は
と書くことができる。機械学習の分野だとこちらの表現のほうが目にするかも。
線形分離可能性#
機械学習として(目的変数の予測が目的)のロジスティック回帰では、線形分離可能な問題であることが嬉しい
統計学としては最尤推定量が存在しない(解が一意に定まらない)という扱いになる様子