統計的裁定#
裁定のように無リスクで収益が得られる機会はないが、無制限に投資期間を延ばせるならリスクの大部分を除去できるような投資戦略のこと。
アプローチは主に2つあるとされる
データ分析や統計学を応用
例:共和分法
経済学的な根拠に基づく方法
例:マーケット中立化法
共和分法#
共和分#
単位根過程(1次の和分過程)
より一般的には
M次元の確率過程
このような
共和分過程であるかどうかの判定→共和分検定#
VECM(vector error correction model)
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from statsmodels.tsa.vector_ar.vecm import coint_johansen
from statsmodels.tsa.api import VECM
Sigma = np.array([[1,0,0],[0,1,0],[0,0,1]])
# 配列を生成
alpha_1 = np.array([0.1,0.2,0.3])
alpha_2_ = np.array([0.5,-0.3,-0.3])
beta_1 = np.array([1,-0.5,-0.5])
beta_2_ = np.array([-0.2,0.5,-0.2])
# 配列から行列を生成
alpha_2 = np.stack([alpha_1, alpha_2_],axis = 1) # alpha_2
beta_2 = np.stack([beta_1, beta_2_]) # beta_2
# 内積計算
Pi_1 = np.dot(alpha_1.reshape(3,1), beta_1.reshape(1,3))
Pi_2 = np.dot(alpha_2, beta_2)
np.random.seed(seed=1)
rand_nums = np.random.randn(10000, 3)
# ランダム・ウォーク、共和分過程の初期化
init = np.array([1,1,1])
S_rw = init
S_ci1 = init
S_ci2 = init
for rand_num in rand_nums:
S_rw = np.vstack((S_rw,S_rw[len(S_rw)-1] + np.dot(rand_num,Sigma)))
S_ci1 = np.vstack((S_ci1,np.dot(Pi_1 + np.eye(3),S_ci1[len(S_ci1)-1])
+ np.dot(rand_num,Sigma)))
S_ci2 = np.vstack((S_ci2,np.dot(Pi_2 + np.eye(3),S_ci2[len(S_ci2)-1])
+ np.dot(rand_num,Sigma)))
#ランダムウォークに対する共和分検定
JohansenTestResult_rw = coint_johansen(S_rw, k_ar_diff=0, det_order=-1)
# 尤度比(likelihood ratio)
# lr1はtrace testに対する統計量、lr2がmax testに対する統計量
print(JohansenTestResult_rw.lr1) # Trace statistic
[17.26191535 5.31491933 0.49706169]
print(JohansenTestResult_rw.cvt) # Critical values (90%,95%,99%) of trace statistic
# 1行目が「ランクが0である」という帰無仮説のtrace testの棄却限界値
# 2行目は「ランクが1である」
[[21.7781 24.2761 29.5147]
[10.4741 12.3212 16.364 ]
[ 2.9762 4.1296 6.9406]]
print(JohansenTestResult_rw.lr2) # Maximum eigenvalue statistic
[11.94699603 4.81785764 0.49706169]
print(JohansenTestResult_rw.cvm) # Critical values (90%,95%,99%) of maximum eigenvalue statistic
[[15.7175 17.7961 22.2519]
[ 9.4748 11.2246 15.0923]
[ 2.9762 4.1296 6.9406]]
statsmodels.tsa.vector_ar.vecm.VECM — statsmodels
statsmodelsによるベクトル誤差修正モデル(VECM)入門 - Qiita
# 計算が重くメモリ消費量も多いので注意
model_s1 = VECM(S_rw, k_ar_diff=0, coint_rank = 1, deterministic='na')
res_s1 = model_s1.fit()
print(res_s1.summary())
Loading coefficients (alpha) for equation y1
==============================================================================
coef std err z P>|z| [0.025 0.975]
------------------------------------------------------------------------------
ec1 -0.0002 0.000 -0.674 0.500 -0.001 0.000
Loading coefficients (alpha) for equation y2
==============================================================================
coef std err z P>|z| [0.025 0.975]
------------------------------------------------------------------------------
ec1 0.0007 0.000 2.096 0.036 4.51e-05 0.001
Loading coefficients (alpha) for equation y3
==============================================================================
coef std err z P>|z| [0.025 0.975]
------------------------------------------------------------------------------
ec1 -0.0005 0.000 -1.495 0.135 -0.001 0.000
Cointegration relations for loading-coefficients-column 1
==============================================================================
coef std err z P>|z| [0.025 0.975]
------------------------------------------------------------------------------
beta.1 1.0000 0 0 0.000 1.000 1.000
beta.2 -0.6171 0.188 -3.282 0.001 -0.986 -0.249
beta.3 1.0580 0.452 2.340 0.019 0.172 1.944
==============================================================================
# 推定されたパラメータ
print(res_s1.alpha)
print(res_s1.beta)
[[-0.00022488]
[ 0.00069615]
[-0.00049745]]
[[ 1. ]
[-0.61713726]
[ 1.05797279]]
(メモ)共和分ベクトルの簡単な例#
は
となり、共和分ベクトルは
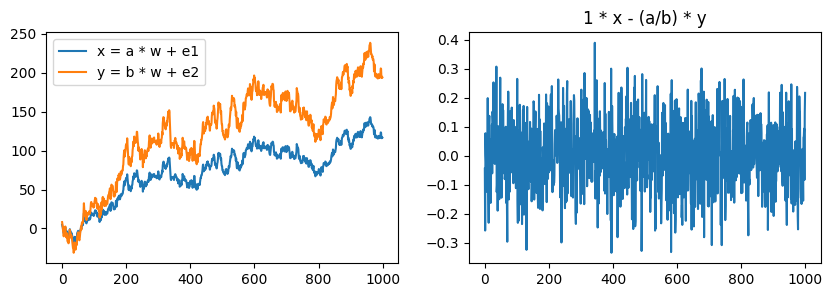
n = 1000
np.random.seed(seed=1)
w = np.random.normal(loc=0, scale=1, size=n)
w = np.cumsum(w) # random walk: w_t = w_{t-1} + w_t'
a, b = 3, 5
e1 = np.random.normal(scale=0.1, size=n)
e2 = np.random.normal(scale=0.1, size=n)
fig, axes = plt.subplots(ncols=2, figsize=[10, 3])
x = a * w + e1
y = b * w + e2
axes[0].plot(x, label="x = a * w + e1")
axes[0].plot(y, label="y = b * w + e2")
axes[0].legend()
new = 1 * x - (a/b) * y
axes[1].plot(new)
axes[1].set(title="1 * x - (a/b) * y")
fig.show()
マーケット中立化法#
最も一般に知られる意味での「マーケット中立」は、市場ポートフォリオの変動に対してパフォーマンスが左右されないポートフォリオというもの。
例えば2つの危険資産
で変動していたとする。ポートフォリオ・ウェイトを
とすると、ポートフォリオのリターンは
となり、ポートフォリオ・リターンを市場ポートフォリオの変動から切り離すことができる。
実際に運用する際はポートフォリオに組み込む資産の数を増やせば固有リスク
ただ中立化するだけでは、ポートフォリオのリターンが安全資産の期待リターンに近づくだけなので、旨味はない。裁定の要素を入れていく必要がある。
裁定価格理論#
代表的投資家の効用関数が平均分散型のとき、均衡はCAPMになる。CAPMが成り立つとき、無裁定である(統計的裁定もとれない)。 しかし、逆は必ずしも真ではない。市場が無裁定でも危険資産がCAPMに従って変動するとは限らない。
CAPMの主張は資産のリスク・プレミアムが市場ポートフォリオのリスク・プレミアムのみに比例するというもの。資産のリスク・プレミアムが他のファクターに依存していたときも無裁定でありうる。
「市場が無裁定のとき、資産のリスク・プレミアムはどのように表されるのか」という問いに答えたのがRoss(1976)の裁定価格理論(arbitrage pricing theory, APT)で、市場が無裁定のとき、危険資産の期待リターンを並べたベクトル
で与えられるというもの。ここで、
CAPMのような1つのファクターで各資産の期待リターンを説明するモデルをシングルファクター・モデルといい、複数のファクターを使うモデルをマルチファクター・モデルとよぶ。
統計的裁定が可能な場合のマーケット中立化法#
市場が無裁定のとき、各資産の期待リターンは
Liu & Timmermann (2013)はポートフォリオをマーケット中立にした上で共和分法を行うシンプルな戦略を提案している。
ディスタンス法#
ディスタンス法はペアーズ・トレーディング(pairs trading)の一つ。
ペアーズ・トレーディングとは、1組のペアからなる株式のポジションをとる戦略である。お互いに似た動きをしていれば、一方をロングすると同時に他方をショートすることで、片方が損失を出してももう片方が利益を生む。
ディスタンス法の狙いは共和分法と同じであり、Rad et al. (2016)によればディスタンス法のパフォーマンスは共和分法のそれと拮抗する。
Gatev et al. (2006)のディスタンス法は以下の通り。
ペアの選定#
銘柄
各時点
配当がある場合は配当
各銘柄の時点
2つの銘柄
この二乗和が小さいペアを「動きが似ている銘柄ペア」としてポートフォリオに選ぶ
取引執行ルール#
ペア選定時に計算した価格差の標準偏差を基準に決める。
価格差の標本標準偏差
で計算できる。
取引期間に入ったら改めて価格を基準化して、価格差
取引期間中に価格差の絶対値が
価格差が再び収束して一致したときにポジションを解消する
ロングするのに必要な資金はショートによって賄うことで初期時点のポートフォリオ価値をゼロにする (→統計的裁定の第一要件
改良ディスタンス法#
Chien et al. (2019)が提案している改良版
銘柄選定について、