予測性能の評価指標(Metrics)#
Regression#
二乗誤差#
誤差を二乗するので、絶対誤差に比べて大きく予測を外した値が強調されるのが特徴。
MSE (Mean Squared Error)#
二乗誤差 \((y_i - \hat{y}_i)^2\) を平均したもの
MSE (Mean Squared Error)
RMSE (Root Mean Squared Error)#
MSEの平方根。元の単位に戻るため比較的解釈しやすい。
RMSE (Root Mean Squared Error)
絶対誤差#
二乗しないため外れ値に強い。
また、ビジネスサイドへの説明も行いやすい。(RMSEは「誤差を二乗して平方根をとったもので⋯」とか説明しても計算が複雑でわかりにくい)
MAE (Mean Absolute Error)#
平均絶対誤差。誤差の絶対値の平均。
MAE (Mean Absolute Error)
絶対誤差の勾配は符号しか残らない
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
Cell In[1], line 7
4 e = np.linspace(-2, 2, 100)
6 plt.figure(figsize=[4,3])
----> 7 plt.plot(x, e**2, label=r"Squared Error $e^2$")
8 plt.plot(x, abs(e), label=r"Absolute Error $|e|$")
10 plt.ylabel(r"$error$")
NameError: name 'x' is not defined
<Figure size 400x300 with 0 Axes>
誤差率#
誤差と真値の比率に基づく指標。これも説明性は高い
(0除算に注意が必要)
MAPE (Mean Absolute Percentage Error)#
平均絶対誤差率。
MAPEに近いのはMAEではなくFair Loss。
MAE、つまり絶対誤差だと勾配をとったときに残差の符号しか残らず、誤差の大きさがわからなくなる。
その点、Fair Lossのほうがいい
(参考:SIGNATE 土地価格コンペ 1位解法)
相関#
相関係数#
予測値と実測値の相関
決定係数#
決定係数。モデルがどれだけ分散を説明できるか。
RMSEとMAE#
どっちがいいか?という議論があるらしい
確率予測#
Calibration Plot#
横軸に予測確率
縦軸には経験確率、つまり「同じくらいの予測確率になったサンプルを集めたときの実際の正例の比率」
を出したプロット
(参考:1.16. Probability calibration — scikit-learn 1.7.2 documentation)

Log Loss(Cross Entropy Loss)#
予測確率の信頼度を含めた誤差指標。確率出力モデルに適する。
from sklearn.metrics import log_loss
log_loss(y_test, y_prob)
0.3873822188513259
Brier Score Loss#
Brier Score は 正解クラスと予測確率の平均二乗誤差(MSE)で定義される指標。低いほど良いのでBrier Score Lossとも呼ばれる。
2クラス分類の場合
2クラス分類の場合は正解クラス\(y_i\)と予測確率\(\hat{p}_i\)により次のように表され、\([0,1]\)の値をとる。
\(C\)クラス分類の場合
一般に\(C\)クラス分類の場合は次のように表され、\([0,2]\)の値をとる。
brier_score_loss — scikit-learn 1.8.0 documentation
from sklearn.metrics import brier_score_loss
brier_score_loss(y_test, y_prob)
0.1209847403686766
二値分類 (Binary Classification)#
特定の閾値の下での評価#
予測値の確率・信頼度を特定の閾値で区切ってPositive/Negativeを出した下での評価指標
混同行列(Confusion Matrix)#
True Positive (TP) と True Negative (TN) に分けられた数の分布を視覚的に判断する
実際\予測 |
Positive |
Negative |
|---|---|---|
Positive |
TP(真陽性) |
FN(偽陰性) |
Negative |
FP(偽陽性) |
TN(真陰性) |
<sklearn.metrics._plot.confusion_matrix.ConfusionMatrixDisplay at 0x7a1796589720>

Accuracy(正解率)#
全体のうち、正しく分類できた割合。
Recall(再現率)#
実際に「正例(Positive)」であるもののうち、正しく予測できた割合。
どれだけFalse Negativeを小さくできたか。
Precision(適合率)#
「正例(Positive)」と予測したうち、実際にPositiveだった割合。
どれだけFalse Positiveを小さくできたか
F1-score#
PrecisionとRecallの調和平均。両者のバランスを取る指標。
PrecisionとRecallにはトレードオフ関係がある(https://datawokagaku.com/f1score/ )ため平均で評価している。
from sklearn.metrics import accuracy_score, recall_score, precision_score, f1_score
for metrics in "accuracy_score, recall_score, precision_score, f1_score".split(", "):
value = eval(f"{metrics}(y_true, y_pred)")
print(f"{metrics}={value:.2}")
accuracy_score=0.64
recall_score=0.17
precision_score=0.12
f1_score=0.14
複数の閾値のもとでの指標#
ROC-AUC(Area Under the ROC Curve)#
ROC曲線(真陽性率 vs 偽陽性率)の下の面積。
1に近いほどモデルの識別能力が高い。
true positive rate \(TPR\)(recallの別名、陽性者を正しく陽性だと当てる率、sensitivityとも)とfalse positive rate \(FPR\)(陰性者のうち偽陽性になる率)
を用いて閾値を変えながら描いた曲線をreceiver operating characteristic(ROC; 受信者操作特性)曲線という。
ROC曲線の下側の面積(Area Under the Curve)をROC-AUCという。ランダムなアルゴリズム(chance level)だとROC-AUCは0.5になる
/tmp/ipykernel_57789/1909585709.py:37: UserWarning: Matplotlib is currently using module://matplotlib_inline.backend_inline, which is a non-GUI backend, so cannot show the figure.
fig.show()

Precision-Recall Curve#
さまざまなthresholdの元でのRecallとPrecisionを算出し、横軸にRecall、縦軸にPrecisionを結んだグラフ
PR曲線の下側の面積(Area Under the Curve)をPR-AUCあるいはAverage Precisionという
ROC曲線とは異なり、「ランダムなアルゴリズムなら0.5」のような安定したスケールではなく、スケールはクラスのバランス(不均衡具合)に依存する
その分、不均衡データにおけるモデル評価に向いていると言われている
/tmp/ipykernel_57789/2352438180.py:18: UserWarning: Matplotlib is currently using module://matplotlib_inline.backend_inline, which is a non-GUI backend, so cannot show the figure.
fig.show()

imbalanced dataとPR曲線・ROC曲線#
ある不均衡データがあったとする
from sklearn.datasets import make_classification
size = 1000
X, y = make_classification(n_samples=size, n_features=2, n_informative=1, n_redundant=1, weights=[0.9, 0.1],
class_sep=0.5, n_classes=2, n_clusters_per_class=1, random_state=0)
import pandas as pd
pd.Series(y).value_counts()
0 894
1 106
Name: count, dtype: int64
accuracy_score=0.9
recall_score=0.26
precision_score=0.55
f1_score=0.36
<sklearn.metrics._plot.confusion_matrix.ConfusionMatrixDisplay at 0x7a179615d9c0>

/tmp/ipykernel_57789/4277730166.py:8: UserWarning: Matplotlib is currently using module://matplotlib_inline.backend_inline, which is a non-GUI backend, so cannot show the figure.
fig.show()

マシューズ相関係数(MCC)#
マシューズ相関係数(Matthews Correlation Coefficient: MCC) は二値分類モデルの性能評価指標の一つで、特にクラスの不均衡がある場合に信頼性が高いことで知られている。
言葉でいうと
分子: 正しく分類された数(TP × TN) から、 誤分類の積(FP × FN) を引いたもの。
分母:全体の規模を正規化(0除算を防ぐため)。
from sklearn.metrics import matthews_corrcoef
y_true = [1, 1, 0, 0, 0, 0, 0]
y_pred = [1, 0, 1, 0, 0, 0, 0]
print(f"MCC: {matthews_corrcoef(y_true, y_pred):.3f}")
# 不均衡なデータに対してMajority Classだけを予測した場合
y_true = [1, 0, 0, 0, 0, 0, 0]
y_pred = [0, 0, 0, 0, 0, 0, 0]
print(f"MCC: {matthews_corrcoef(y_true, y_pred):.3f}")
MCC: 0.300
MCC: 0.000
Balanced Accuracy#
Balanced Accuracy は、各クラスの正解率(リコール、感度)を平均したもの
ここで:
\(\frac{TP}{TP + FN}\):感度(Sensitivity)または再現率(Recall)
\(\frac{TN}{TN + FP}\):特異度(Specificity)
不均衡データに強いとされる。
from sklearn.metrics import accuracy_score, balanced_accuracy_score
# 不均衡なデータに対してMajority Classだけを予測した場合
y_true = [1, 0, 0, 0, 0, 0, 0]
y_pred = [0, 0, 0, 0, 0, 0, 0]
print(f"accuracy: {accuracy_score(y_true, y_pred):.3f}")
print(f"balanced_accuracy: {balanced_accuracy_score(y_true, y_pred):.3f}")
accuracy: 0.857
balanced_accuracy: 0.500
多クラス分類(Multiclass Classification)#
Macro F1#
各クラスのF1スコアを単純平均したもの。クラス不均衡に弱い。
各クラスを等しく扱う。
Micro F1#
全サンプルのTP・FP・FNを合計してからF1を計算。
サンプル数の多いクラスに影響されやすい。
Weighted F1#
各クラスのF1をクラスのサンプル数で重み付けして平均。
クラス不均衡データに適する。
ランキング・推薦(Ranking / Recommender)#
Precision@k#
上位 \(k\) 件の予測のうち、正解が占める割合。
Recall@k#
上位 \(k\) 件が、全正解のうちどれだけをカバーしたか。
MAP(Mean Average Precision)#
各クエリに対する平均適合率(AP)を平均化したもの。
NDCG(Normalized Discounted Cumulative Gain)#
順位の高い正解をより高く評価する。上位の重要性を考慮。
MRR(Mean Reciprocal Rank)#
最初の正解が出現する順位の逆数を平均。
類似度#
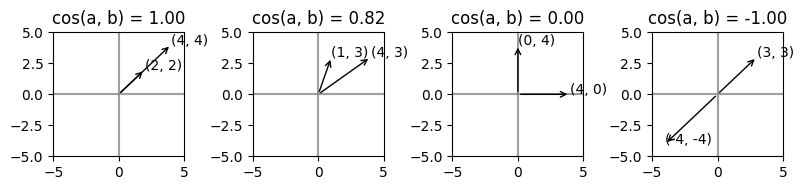
コサイン類似度#
ベクトルの方向が似ているものは似ている
コサイン類似度(Cosine Similarity)とは?:AI・機械学習の用語辞典 - @IT
2つのベクトルがなす角(コサイン)の値が類似度として使える、ということになる
KLダイバージェンス#
2つの分布\(p(x), q(x)\)に対する距離のようなもの。ただし、非対称(\(\operatorname{KL}(p\|q) \ne \operatorname{KL}(q\|p)\))である。
確率密度関数 \(p(x)\), \(q(x)\) に対して:
性質
非負性:\(\operatorname{KL}(p\|q) \ge 0\)
等号成立は \(p(x)=q(x)\) のときのみ。(証明は Jensen の不等式)
非対称:\(\operatorname{KL}(p\|q) \neq \operatorname{KL}(q\|p)\)
対称性を持たせたい場合は Jensen–Shannon divergence を使う
\(\operatorname{KL}(p\|q) = 0 \implies p = q\)
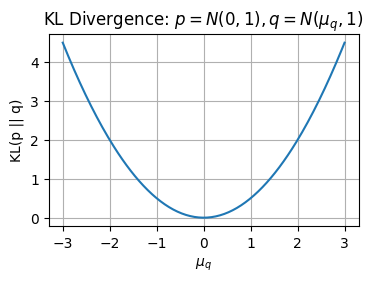
KLダイバージェンス≒2乗誤差
正規分布同士のKLダイバージェンスは
となる。両方の分布の分散を1に固定すると
となり、 2つの分布の平均\(\mu_p, \mu_q\)についての二乗誤差 であることがわかる。
(参考)1変量正規分布同士のKLダイバージェンスの導出
1 次元の正規分布 \(p(x) = \mathcal{N}(\mu_0, \sigma_0^2)\)、\(q(x) = \mathcal{N}(\mu_1, \sigma_1^2)\) に対して\(\operatorname{KL}(p\|q)\) を定義から導く。
KL ダイバージェンスの定義は
正規分布の密度は
1. 対数比とその期待値について
対数比 \(\log \dfrac{p(x)}{q(x)}\) をとる:
KLダイバージェンスは対数比の期待値であるため
なので、残りは \(\mathbb{E}_p[(X-\mu_0)^2]\) と \(\mathbb{E}_p[(X-\mu_1)^2]\) を評価すればよい。
2. \(\mathbb{E}_p[(X-\mu_0)^2]\) について
\(\mathbb{E}_p[(X-\mu_0)^2] = \operatorname{Var}_p(X) = \sigma_0^2\) であるため、
とシンプルにできる。
3. \(\mathbb{E}_p[(X-\mu_1)^2]\) について
\((X-\mu_1)\) に\(\mu_0\)を足して引いて \((X-\mu_0)+(\mu_0-\mu_1)\) に分解する:
これを \(p\) に関する期待値にすると:
ここで
\(\mathbb{E}_p[(X-\mu_0)^2] = \sigma_0^2\)
\(\mathbb{E}_p[X-\mu_0] = 0\)
なので、
したがって
4. まとめ
以上をまとめると
よって、1 次元正規分布どうしの KL ダイバージェンスは
となる。