最適ポートフォリオ#
時点
期待リターンは
ボラティリティは
と定義される。
ボラティリティの大きさをリスクという。
2資産モデル#
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import japanize_matplotlib
# stock 1
mu1, sigma1 = (0.1, 0.1)
# stock 2
mu2, sigma2 = (0.4, 0.3)
mu = np.array([mu1, mu2])
sigma = np.array([sigma1, sigma2])
ポートフォリオの期待リターンは
(ここで
ポートフォリオのボラティリティは
ここで
def Sigma(rho):
"""共分散行列。ρ_{2,1} = ρ_{1,2}の想定"""
return np.array([
[sigma1**2, sigma1 * sigma2 * rho],
[sigma1 * sigma2 * rho, sigma2**2],
])
Sigma(rho=.1)
array([[0.01 , 0.003],
[0.003, 0.09 ]])
# ポートフォリオ・ウェイト(値は適当)
pi = np.array([0.5, 0.5])
# ポートフォリオの期待リターン
mu_P = pi.T @ mu
# ポートフォリオのボラティリティ
sigma_P = np.sqrt(pi.T @ Sigma(rho=.1) @ pi)
これらを使って、ポートフォリオ・ウェイトや銘柄間の相関係数を変えながらプロットすると以下のようになる
Show code cell source
import itertools
mu_Ps = []
sigma_Ps = []
rhos = []
# ポートフォリオ・ウェイトの組み合わせ
pi1 = np.linspace(0, 1, 51)
pi2 = 1 - pi1
pi_range = np.array([pi1, pi2])
# 相関係数
# rho_range = np.linspace(-1, 1, 21)
rho_range = [-1, -.5, 0, .5, 1]
# 変数を変えていったときのポートフォリオのボラティリティ
for pi, rho in itertools.product(pi_range.T, rho_range):
mu_P = pi.T @ mu # ポートフォリオの期待リターン
sigma_P = np.sqrt(pi.T @ Sigma(rho) @ pi) # ポートフォリオのボラティリティ
mu_Ps.append(mu_P)
sigma_Ps.append(sigma_P)
rhos.append(rho)
mu_Ps = np.array(mu_Ps)
sigma_Ps = np.array(sigma_Ps)
rhos = np.array(rhos)
# plot
fig, ax = plt.subplots()
sns.scatterplot(
x="sigma", y="mu", hue="rho",
data = pd.DataFrame({"mu": mu_Ps, "sigma": sigma_Ps, "rho": rhos}),
ax=ax
)
ax.set(xlabel="volatility", ylabel="expected return", xlim=[-0.01, 0.31], ylim=[-0.01, 0.45])
ax.grid(True)
fig.show()
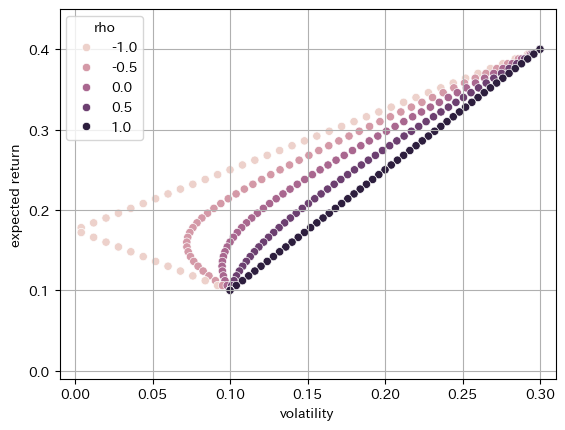
ここからの含意:
高い期待リターンを狙えばボラティリティも高くなる
期待リターンを下げすぎてもボラティリティが高くなる(
危険資産のみのポートフォリオの最適化#
3資産以上になると、投資可能集合は線ではなく面になる。この面を実行可能領域とよぶ。
実現可能領域を包む境界線を平均分散フロンティア(mean variance frontier)といい、その上半分を「平均分散フロンティアの効率パート」、略して効率的フロンティアと呼ぶ。(下半分は低い期待リターンに対してボラティリティが高いため合理的ではない)
Show code cell source
# # 曲線を描こうとしたがうまくいかなかった残骸
# def frontier(sigma_P, rho, mu=mu):
# """-1 < ρ < 1 のときの平均分散フロンティアの曲線"""
# ones = np.ones(shape=(len(mu), ))
# A = mu.T @ np.linalg.inv(Sigma(rho)) @ mu
# B = ones.T @ np.linalg.inv(Sigma(rho)) @ mu
# C = ones.T @ np.linalg.inv(Sigma(rho)) @ ones
# D = (sigma_P ** 2 / (1 / C))
# mu_P = np.sqrt( ((A * C - B ** 2) / C ** 2) * (1 + D) ) + (B / C)
# return mu_P
# mu_P_hats = []
# sigma_Ps = []
# # 相関係数
# rho_range = np.linspace(-0.9, 0.9, 21)
# # rho_range = [-0.9, -.5, 0, .5, 0.9]
# # 変数を変えていったときのポートフォリオのボラティリティ
# for pi, rho in itertools.product(pi_range.T, rho_range):
# # mu_P = pi.T @ mu # ポートフォリオの期待リターン
# sigma_P = np.sqrt(pi.T @ Sigma(rho) @ pi) # ポートフォリオのボラティリティ
# mu_P_hat = frontier(sigma_P, rho)
# mu_P_hats.append(mu_P_hat)
# sigma_Ps.append(sigma_P)
# fig, ax = plt.subplots()
# ax.scatter(sigma_Ps, mu_P_hats)
# plot ------------------------------------
rows = []
# 相関係数
rho_range = [-0.9]
# 変数を変えていったときのポートフォリオのボラティリティ
for pi, rho in itertools.product(pi_range.T, rho_range):
mu_P = pi.T @ mu # ポートフォリオの期待リターン
sigma_P = np.sqrt(pi.T @ Sigma(rho) @ pi) # ポートフォリオのボラティリティ
rows.append({"mu": mu_P, "sigma": sigma_P, "rho": rho})
data = pd.DataFrame(rows)
# plot
fig, ax = plt.subplots()
ax.plot(data["sigma"], data["mu"], color="steelblue")
ax.fill(data["sigma"], data["mu"], color="lightblue")
ax.set(xlabel="volatility", ylabel="expected return", xlim=[-0.01, 0.31], ylim=[-0.01, 0.45])
ax.grid(True)
fig.show()
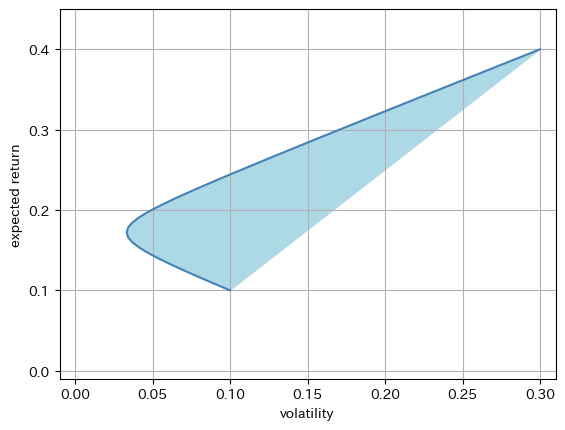
安全資産を含むポートフォリオの最適化#
Show code cell source
# # safe asset
# mu0, sigma0 = (0.05, 0.0)
# # stock 1
# mu1, sigma1 = (0.4, 0.3)
# mu = np.array([mu0, mu1])
# sigma = np.array([sigma0, sigma1])
# import itertools
# mu_Ps = []
# sigma_Ps = []
# rhos = []
# # ポートフォリオ・ウェイトの組み合わせ
# pi1 = np.linspace(0, 1, 51)
# pi2 = 1 - pi1
# pi_range = np.array([pi1, pi2])
# # 相関係数
# # rho_range = np.linspace(-1, 1, 21)
# rho_range = [-1, -.5, 0, .5, 1]
# # 変数を変えていったときのポートフォリオのボラティリティ
# for pi, rho in itertools.product(pi_range.T, rho_range):
# mu_P = pi.T @ mu # ポートフォリオの期待リターン
# sigma_P = np.sqrt(pi.T @ Sigma(rho) @ pi) # ポートフォリオのボラティリティ
# mu_Ps.append(mu_P)
# sigma_Ps.append(sigma_P)
# rhos.append(rho)
# mu_Ps = np.array(mu_Ps)
# sigma_Ps = np.array(sigma_Ps)
# rhos = np.array(rhos)
# # plot
# fig, ax = plt.subplots()
# sns.scatterplot(
# x="sigma", y="mu", hue="rho",
# data = pd.DataFrame({"mu": mu_Ps, "sigma": sigma_Ps, "rho": rhos}),
# ax=ax
# )
# ax.set(xlabel="volatility", ylabel="expected return", xlim=[-0.01, 0.31], ylim=[-0.01, 0.45])
# ax.grid(True)
# fig.show()
# safe asset
mu0, sigma0 = (0.03, 0.0)
# risk asset only portfolios
risk_Ps = pd.DataFrame({"mu": mu_Ps, "sigma": sigma_Ps, "rho": rhos})
# 危険資産ポートフォリオへのウェイトt
ts = np.linspace(0, 1, 11)
results = []
for t in ts:
for _, row in risk_Ps.iterrows():
mu_P = t * row["mu"] + (1 - t) * mu0
sigma_P = row["sigma"]
results.append({"mu": mu_P, "sigma": sigma_P, "t": t})
results = pd.DataFrame(results).drop_duplicates()
# plot
fig, ax = plt.subplots()
sns.scatterplot(
x="sigma", y="mu", hue="t",
data=results,
ax=ax
)
ax.set(xlabel="volatility", ylabel="expected return", xlim=[-0.01, 0.31], ylim=[-0.01, 0.45])
ax.grid(True)
fig.show()
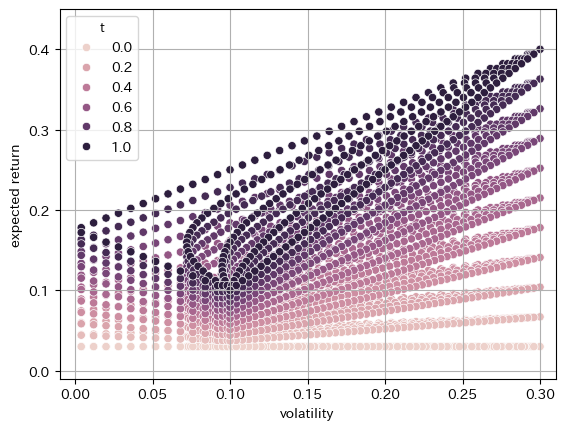
危険資産だけからなる平均分散フロンティアと危険資産に安全資産を加えたポートフォリオの効率的フロンティアの接点のポートフォリオを接点ポートフォリオ(tangency portfolio)という。
接点ポートフォリオのポートフォリオ・ウェイトは
である
Show code cell source
# rows = []
# # 相関係数
# rho_range = [-0.9, 0.5, 0]
# for rho in rho_range:
# # 接点ポートフォリオのウェイト
# s = np.linalg.inv(Sigma(rho=0.1)) @ (mu - mu0 * ones)
# pi = s / (ones.T @ s)
# mu_P = pi.T @ mu # ポートフォリオの期待リターン
# sigma_P = np.sqrt(pi.T @ Sigma(rho) @ pi) # ポートフォリオのボラティリティ
# rows.append({"mu": mu_P, "sigma": sigma_P, "rho": rho})
# data = pd.DataFrame(rows)
# # plot
# fig, ax = plt.subplots()
# ax.plot(data["sigma"], data["mu"], color="steelblue")
# ax.fill(data["sigma"], data["mu"], color="lightblue")
# ax.set(xlabel="volatility", ylabel="expected return", xlim=[-0.01, 0.31], ylim=[-0.01, 0.45])
# ax.grid(True)
# fig.show()
接点ポートフォリオの期待リターンは
効率的フロンティアは切片が
となる。
合理的な投資家は効率的フロンティア上でポートフォリオを組みたいと考えるはずなので、シャープ・レシオは全員同じ値になると考えられる。危険資産を組み替えれば平均分散フロンティアの形状は変わり接点ポートフォリオの位置も変わるため、シャープ・レシオは変わる。シャープ・レシオを改善するためには組み込む危険資産の構成を工夫するしかない
目標とする期待リターンとそれに対応するボラティリティは上の平均分散フロンティア上にあるので、上の式は次のように書くこともできる
トービンの分離定理#
最適な安全資産ポートフォリオ・ウェイトは
ポートフォリオの期待リターン
危険資産のポートフォリオ・ウェイトを決める作業は選好とは関係なく決まる。 投資家の選好に応じて変わるのは、ポートフォリオ全体の目標期待リターンを定める作業。 このことはトービンの分離定理(separation theorem)と言われる(Tobin 1958)。
トービンの分離定理
安全資産がある場合、効率的フロンティア上の任意のポートフォリオ(効率的ポートフォリオ)は、安全資産と接点ポートフォリオを適切な投資比率で組み合わせることによって実現できる。
参考#
吉川 大介(2022)『データ駆動型ファイナンス』、共立出版。