線形回帰#
モデル#
線形回帰(linear regression)は、予測の目的変数\(y\)と特徴量(説明変数)\(x_1, x_2, ..., x_d\)の間に次のような線形関係を仮定したモデルを置いて予測する手法。 $\( y = \beta_0 + \beta_1 x_1 + \cdots + \beta_d x_d + \varepsilon \)$
ここで\(\beta_1, \beta_2, ..., \beta_d\)は回帰係数と呼ばれるパラメータで、モデル内で推定される。\(\varepsilon\)はデータ取得時の測定誤差などの偶然による誤差を表し、次の3つの条件を満たす。
期待値は0:\(\text{E}[\varepsilon]=0\)
分散は一定: \(\text{V}[\varepsilon]=\sigma^2\)
異なった誤差項は無相関: \(j \neq i\)ならば\(Cov(\varepsilon_i, \varepsilon_j) = E(\varepsilon_i, \varepsilon_j) = 0\)
サンプルサイズが\(n\)のデータセット\(\{\boldsymbol{x}_i, y_i\}^n_{i=1}\)があるとして、目的変数を\(\boldsymbol{y} = (y_1, y_2, ..., y_n)^\top\)、特徴量を\(\boldsymbol{X}=(\boldsymbol{x}_1, \boldsymbol{x}_2, ..., \boldsymbol{x}_n)^\top\)とおくと、このモデルは
と表記することができる。
パラメータの推定#
一般的に線形回帰ではパラメータの推定に最小二乗法(least squares method)という方法が使われる。
これは誤差関数\(J( \boldsymbol{\beta})\)を実測値\(\boldsymbol{y}\)と予測値\(\hat{\boldsymbol{y}} = \boldsymbol{X}\hat{\boldsymbol{\beta}}\)の二乗誤差の和(誤差二乗和 sum of squared error: SSE)
として定義し、この二乗誤差を最小にするパラメータ(最小二乗推定量 ordinary least square’s estimator: OLSE)
を採用するという方法。
二乗誤差\((y_i - \hat{y}_i)^2 = \varepsilon_i^2\)はU字型になるため傾きがゼロになる点が最小値になる。そのため最小二乗法は解析的に解を求めることができる。

誤差二乗和は
であるから、二乗誤差の傾きがゼロになる点は
と表すことができる。
これを整理して
これの両辺を2で割ると(あるいは誤差関数の定義の際に\(1/2\)を掛けておくと)、正規方程式(normal equation)とよばれる次の式が得られる。
これを\(\boldsymbol{\beta}\)について解けば
となり、最小二乗推定量\(\hat{\boldsymbol{\beta}}^{LS}\)が得られる。
実装#
numpyでは、行列やベクトルの積は@という演算子で書くことができる。そのため、
import numpy as np
beta = np.linalg.inv(X.T @ X) @ X.T @ y
のように書けば上の式とおなじ演算を行うことができる。
データの準備#
乱数を発生させて架空のデータを作る。
ここで\(\varepsilon\)は測定誤差などのランダムなノイズとする
import numpy as np
import pandas as pd
n = 100 # sample size
np.random.seed(0)
x0 = np.ones(shape=(n, ))
x1 = np.random.uniform(0, 10, size=n)
x2 = np.random.normal(3, 1, size=n)
noise = np.random.normal(size=n)
beta = [10, 3, 5] # 真の回帰係数
y = beta[0] * x0 + beta[1] * x1 + beta[2] * x2 + noise
特徴量\(x\)と目的変数\(y\)の関係を散布図で描くと次の図のようになった。
[Text(0.5, 0, 'x2'), Text(0, 0.5, 'y')]

推定#
これらのデータを使用して推定を行う。
X = np.array([x0, x1, x2]).T
# Xの冒頭5行は以下のようになっている
print(X[0:5])
[[1. 5.48813504 1.83485016]
[1. 7.15189366 3.90082649]
[1. 6.02763376 3.46566244]
[1. 5.44883183 1.46375631]
[1. 4.23654799 4.48825219]]
# 最小二乗法で推定
beta_ = np.linalg.inv(X.T @ X) @ X.T @ y
print(f"""
推定された回帰係数: {beta_.round(3)}
データ生成過程の係数: {beta}
""")
推定された回帰係数: [9.564 2.98 5.119]
データ生成過程の係数: [10, 3, 5]
真の値にそれなりに近い回帰係数が推定できた。
なお、scikit-learnに準拠したfit/predictのメソッドを持つ形でクラスとして定義するなら、以下のようになる(参考: sklearn準拠モデルの作り方 - Qiita)。
# scikit-learnに準拠した形で実装
from sklearn.base import BaseEstimator, RegressorMixin
class LinearRegression(BaseEstimator, RegressorMixin):
def fit(self, X, y):
self.coef_ = np.linalg.inv(X.T @ X) @ X.T @ y
return self
def predict(self, X):
return X @ self.coef_
model = LinearRegression()
model.fit(X, y)
model.coef_
array([9.56372548, 2.97972446, 5.11931302])
予測してみる#
root mean squared error (RMSE)
を使って予測値を評価してみる。
# 予測値を算出
y_pred = model.predict(X)
# 予測誤差を評価
from sklearn.metrics import mean_squared_error
rmse = mean_squared_error(y, y_pred, squared=False)
print(f"RMSE: {rmse:.3f}")
---------------------------------------------------------------------------
TypeError Traceback (most recent call last)
Cell In[8], line 6
4 # 予測誤差を評価
5 from sklearn.metrics import mean_squared_error
----> 6 rmse = mean_squared_error(y, y_pred, squared=False)
8 print(f"RMSE: {rmse:.3f}")
File ~/work/notes/notes/.venv/lib/python3.10/site-packages/sklearn/utils/_param_validation.py:194, in validate_params.<locals>.decorator.<locals>.wrapper(*args, **kwargs)
191 func_sig = signature(func)
193 # Map *args/**kwargs to the function signature
--> 194 params = func_sig.bind(*args, **kwargs)
195 params.apply_defaults()
197 # ignore self/cls and positional/keyword markers
File ~/.local/share/uv/python/cpython-3.10-linux-x86_64-gnu/lib/python3.10/inspect.py:3186, in Signature.bind(self, *args, **kwargs)
3181 def bind(self, /, *args, **kwargs):
3182 """Get a BoundArguments object, that maps the passed `args`
3183 and `kwargs` to the function's signature. Raises `TypeError`
3184 if the passed arguments can not be bound.
3185 """
-> 3186 return self._bind(args, kwargs)
File ~/.local/share/uv/python/cpython-3.10-linux-x86_64-gnu/lib/python3.10/inspect.py:3175, in Signature._bind(self, args, kwargs, partial)
3173 arguments[kwargs_param.name] = kwargs
3174 else:
-> 3175 raise TypeError(
3176 'got an unexpected keyword argument {arg!r}'.format(
3177 arg=next(iter(kwargs))))
3179 return self._bound_arguments_cls(self, arguments)
TypeError: got an unexpected keyword argument 'squared'
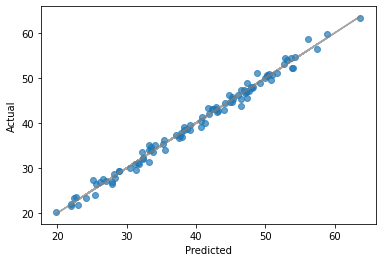
予測値と実測値の散布図を描くと次のようになった。
[Text(0.5, 0, 'Predicted'), Text(0, 0.5, 'Actual')]