分位点回帰#
分位点\(\tau\)における条件付分位関数を
と表す。ここで\(F_y^{-1}(\tau | X_i)\)は\(y\)において\(X_i\)に条件づけられた\(y_i\)の分布関数である(\(F_y^{-1}(\tau | X_i) = \inf \{ y: F_y(y|X_i) \geq \tau \}\))。
例えば\(\tau = 0.1\)のとき、\(Q_\tau(y_i | X_i)\)は\(y_i\)の下位10分位である。
標準的な回帰モデルは二乗誤差\((y_i - m(X_i))^2\)の和や期待値を最小化するようにモデル\(m(X_i)\)を学習して条件付き期待値\(E(y_i|X_i)\)を予測する
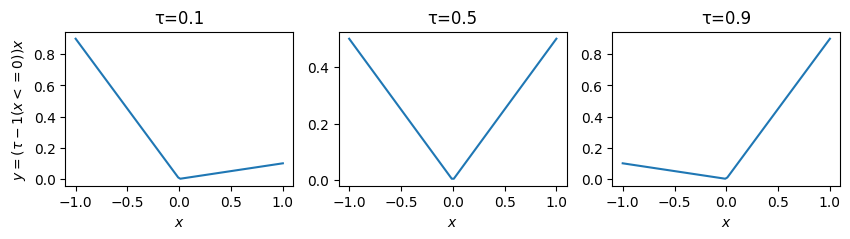
分位点回帰 (quantile regression)モデルはpinball loss\(\rho_{\tau}(y_i - q(X_i))\)の和や期待値を最小化するようにモデル\(q(X_i)\)を学習させ、条件付き分位関数\(Q_{\tau}(y_i|X_i) = F^{-1}_y(\tau|X_i)\)を予測する
pinball lossは \(\tau\)-tiled absolute value function や 検定関数(check function)とも呼ばれる(グラフを描くとチェックマークに似てるため)
あるいは
と書かれる
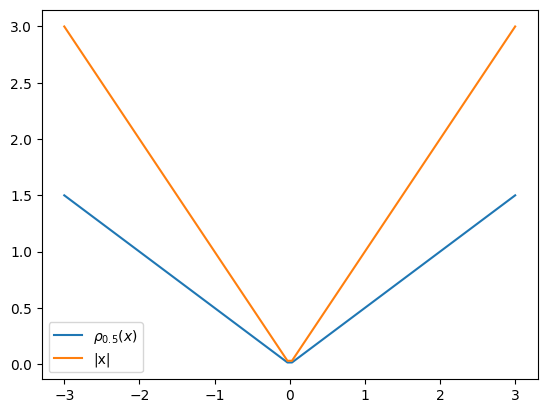
なお、pinball lossは\(\tau=0.5\)のとき
と、絶対誤差と比例する形になる。
絶対誤差の和を目的関数にとった線形モデルは統計学においてleast absolute deviations (LAD) と呼ばれ、その解は条件付き中央値になる
絶対誤差の最適解
誤差関数\(\ell(y, \hat{y})\)を絶対誤差\(|y - \hat{y}|\)とする。予測損失(期待予測誤差)は
絶対値の中身の符号で場合分けすると
予測損失を微分するとそれぞれの項は
よって
となる。\(\frac{d R(\hat{y})}{d \hat{y}}=0\)とおいて整理すれば
となる点が予測損失を極小化することがわかる。これは\(\hat{y}\)が中央値となるときである。
\(f(y)\)は確率密度関数なので、\(\int_{-\infty}^{\infty} f(y) dy=1\)になる。\(-\infty\)から\(\hat{y}\)への積分と\(\hat{y}\)から\(\infty\)への積分が等しくなるのはその半分、すなわち
である。なお、これは累積分布関数\(\mathrm{P}(\hat{y})\)に等しい。よって\(\hat{y}\)は中央値である。
なお、中央値の定義には、以下の式を満たす\(m\)
というものもある。
定積分の定義
より、この導関数は
Pinball lossの最適解
Pinball Lossを少し表現を変えて
と表すと、さきほどの絶対誤差の場合分けした項に\(\tau, (1 - \tau)\)を掛けた形になる
絶対誤差の場合と同様に導関数は
となる。ここで累積分布関数\(F(\hat{y})\)と補累積分布関数をそれぞれ
とおき、導関数を0とおく。
これを整理すると
となり、累積分布\(F(\hat{y})\)で表される確率(分布のうち\(Y\)が\(-\infty\) から \(\hat{y}\)までの面積)が\(\tau\)になることがわかる。 逆関数をとると
となる。累積分布関数の逆関数は分位点なので、\(\hat{y}\)は確率\(\tau\)に対応する分位点である。
モデルの評価#
D2 pinball score#
\(D^2\)は\(R^2\)の一般化
ここで\(y_{\text{null}}\)は切片のみのモデルの最適解(例:二乗誤差なら\(y\)の平均値、絶対誤差なら\(y\)の中央値、pinball lossなら\(y\)の指定されたquantile)
この\(D^2\)に
を代入したものが\(D^2\) pinball score
interval score#
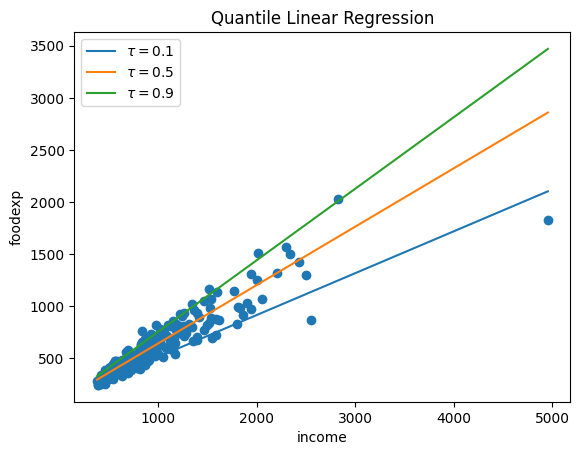
分位点回帰モデルの実践#
statsmodelsでは quantreg() で実行できる
Quantile regression - statsmodels 0.15.0 (+213)
/tmp/ipykernel_1497/2518785238.py:2: DeprecationWarning:
Pyarrow will become a required dependency of pandas in the next major release of pandas (pandas 3.0),
(to allow more performant data types, such as the Arrow string type, and better interoperability with other libraries)
but was not found to be installed on your system.
If this would cause problems for you,
please provide us feedback at https://github.com/pandas-dev/pandas/issues/54466
import pandas as pd