相関係数#
ピアソンの積率相関係数#
ピアソンの積率相関係数
ピアソンの積率相関係数(標本レベル)
どうやって
結論:コーシー・シュワルツの不等式を確率変数にあてはめている。
前提:内積#
ベクトル空間(要素間の和と定数倍が定義された集合であり、和と定数倍の結果もまた集合の要素であるような集合)における内積について触れておく。
(1)
(2)
(3)
(4)
また、内積
というものが存在する。
なお、
具体的な内積の例#
実数空間
標本レベルの話#
またそれらから平均値
標本共分散
よって
したがってコーシー・シュワルツの定理
より、相関係数の範囲は
期待値と内積#
つづいて母集団レベルの話。
確率変数
(1)
(2)
(3)
(4)
相関係数の導出#
コーシー・シュワルツの不等式の内積
を用いる。
とおくと
幾何学的解説#

注意点#
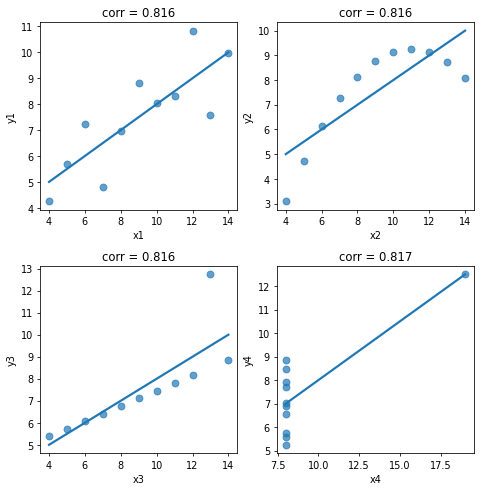
データの関係性をざっくり表すのが相関係数の良さだが、散布図でみると全然異なるデータであってもたまたま同じ相関係数になることがある。また外れ値にひっぱられる特性もある。
下の図はアンスコムの例と呼ばれる、線形回帰をしたときに同じ傾き係数になるデータセット。 相関係数だと線形回帰と違って切片部分がないため係数は若干異なるがだいたい同じになる。
Show code cell source
import statsmodels.api as sm
import pandas as pd
anscombe = sm.datasets.get_rdataset("anscombe").data
import matplotlib.pyplot as plt
import seaborn as sns
fig, axes = plt.subplots(ncols=2, nrows=2, figsize=[8,8], dpi=70)
axes = axes.flatten()
fig.subplots_adjust(hspace=0.3)
for i in range(4):
corr = anscombe.filter(regex=f"{i+1}").corr().iloc[0,1]
sns.regplot(data=anscombe, x=f"x{i+1}", y=f"y{i+1}", ax=axes[i],
ci=None, scatter_kws={"s": 50, "alpha": 0.7})
axes[i].set(title=f"corr = {corr:.3f}")