DoubleMLパッケージによるDMLのシミュレーション#
参考:Python: Basics of Double Machine Learning — DoubleML documentation
import warnings
import numpy as np
from scipy import stats
import matplotlib.pyplot as plt
import seaborn as sns
from lightgbm import LGBMRegressor
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import train_test_split
from sklearn.base import clone
from doubleml import DoubleMLData
from doubleml import DoubleMLPLR
from doubleml.datasets import make_plr_CCDDHNR2018
face_colors = sns.color_palette('pastel')
edge_colors = sns.color_palette('dark')
warnings.filterwarnings("ignore")
np.random.seed(1234)
n_rep = 1000
n_obs = 500
n_vars = 5
alpha = 0.5
data = list()
for i_rep in range(n_rep):
(x, y, d) = make_plr_CCDDHNR2018(alpha=alpha, n_obs=n_obs, dim_x=n_vars, return_type='array')
data.append((x, y, d))
naiive estimator#
\[
\hat{\theta}_0 = \left(\frac{1}{n} \sum_{i\in I} D_i^2\right)^{-1} \frac{1}{n} \sum_{i\in I} D_i (Y_i - \hat{g}_0(X_i)).
\]
def non_orth_score(y, d, l_hat, m_hat, g_hat, smpls):
u_hat = y - g_hat
psi_a = -np.multiply(d, d)
psi_b = np.multiply(d, u_hat)
return psi_a, psi_b
なお、\(\hat{g}_0(X)\)は直接推定できないため間接的に推定している
np.random.seed(1111)
ml_l = LGBMRegressor(n_estimators=300, learning_rate=0.1)
ml_m = LGBMRegressor(n_estimators=300, learning_rate=0.1)
ml_l = RandomForestRegressor(n_estimators=100, max_features=10, max_depth=5, min_samples_leaf=5)
ml_m = RandomForestRegressor(n_estimators=200, max_features=10, max_depth=5, min_samples_leaf=5)
ml_g = clone(ml_l)
theta_nonorth = np.full(n_rep, np.nan)
se_nonorth = np.full(n_rep, np.nan)
for i_rep in range(n_rep):
print(f'Replication {i_rep+1}/{n_rep}', end='\r')
(x, y, d) = data[i_rep]
# choose a random sample for training and estimation
i_train, i_est = train_test_split(np.arange(n_obs), test_size=0.5, random_state=42)
# fit the ML algorithms on the training sample
ml_l.fit(x[i_train, :], y[i_train])
ml_m.fit(x[i_train, :], d[i_train])
psi_a = -np.multiply(d[i_train] - ml_m.predict(x[i_train, :]), d[i_train] - ml_m.predict(x[i_train, :]))
psi_b = np.multiply(d[i_train] - ml_m.predict(x[i_train, :]), y[i_train] - ml_l.predict(x[i_train, :]))
theta_initial = -np.nanmean(psi_b) / np.nanmean(psi_a)
ml_g.fit(x[i_train, :], y[i_train] - theta_initial * d[i_train])
# create out-of-sample predictions
l_hat = ml_l.predict(x[i_est, :])
m_hat = ml_m.predict(x[i_est, :])
g_hat = ml_g.predict(x[i_est, :])
external_predictions = {
'd': {
'ml_l': l_hat.reshape(-1, 1),
'ml_m': m_hat.reshape(-1, 1),
'ml_g': g_hat.reshape(-1, 1)
}
}
obj_dml_data = DoubleMLData.from_arrays(x[i_est, :], y[i_est], d[i_est])
obj_dml_plr_nonorth = DoubleMLPLR(obj_dml_data,
ml_l, ml_m, ml_g,
n_folds=2,
score=non_orth_score)
obj_dml_plr_nonorth.fit(external_predictions=external_predictions)
theta_nonorth[i_rep] = obj_dml_plr_nonorth.coef[0]
se_nonorth[i_rep] = obj_dml_plr_nonorth.se[0]
fig_non_orth, ax = plt.subplots(constrained_layout=True);
ax = sns.histplot((theta_nonorth - alpha)/se_nonorth,
color=face_colors[0], edgecolor = edge_colors[0],
stat='density', bins=30, label='Non-orthogonal ML');
ax.axvline(0., color='k');
xx = np.arange(-5, +5, 0.001)
yy = stats.norm.pdf(xx)
ax.plot(xx, yy, color='k', label='$\\mathcal{N}(0, 1)$');
ax.legend(loc='upper right', bbox_to_anchor=(1.2, 1.0));
ax.set_xlim([-6., 6.]);
ax.set_xlabel('$(\hat{\\theta}_0 - \\theta_0)/\hat{\sigma}$');
plt.show()
Replication 1/1000
Replication 2/1000
Replication 3/1000
Replication 4/1000
Replication 5/1000
Replication 6/1000
Replication 7/1000
Replication 8/1000
Replication 9/1000
Replication 10/1000
Replication 11/1000
Replication 12/1000
Replication 13/1000
Replication 14/1000
Replication 15/1000
Replication 16/1000
Replication 17/1000
Replication 18/1000
Replication 19/1000
Replication 20/1000
Replication 21/1000
Replication 22/1000
Replication 23/1000
Replication 24/1000
Replication 25/1000
Replication 26/1000
Replication 27/1000
Replication 28/1000
Replication 29/1000
Replication 30/1000
Replication 31/1000
Replication 32/1000
Replication 33/1000
Replication 34/1000
Replication 35/1000
Replication 36/1000
Replication 37/1000
Replication 38/1000
Replication 39/1000
Replication 40/1000
Replication 41/1000
Replication 42/1000
Replication 43/1000
Replication 44/1000
Replication 45/1000
Replication 46/1000
Replication 47/1000
Replication 48/1000
Replication 49/1000
Replication 50/1000
Replication 51/1000
Replication 52/1000
Replication 53/1000
Replication 54/1000
Replication 55/1000
Replication 56/1000
Replication 57/1000
Replication 58/1000
Replication 59/1000
Replication 60/1000
Replication 61/1000
---------------------------------------------------------------------------
KeyboardInterrupt Traceback (most recent call last)
Cell In[3], line 22
20 # fit the ML algorithms on the training sample
21 ml_l.fit(x[i_train, :], y[i_train])
---> 22 ml_m.fit(x[i_train, :], d[i_train])
24 psi_a = -np.multiply(d[i_train] - ml_m.predict(x[i_train, :]), d[i_train] - ml_m.predict(x[i_train, :]))
25 psi_b = np.multiply(d[i_train] - ml_m.predict(x[i_train, :]), y[i_train] - ml_l.predict(x[i_train, :]))
File ~/work/notes/notes/.venv/lib/python3.10/site-packages/sklearn/base.py:1389, in _fit_context.<locals>.decorator.<locals>.wrapper(estimator, *args, **kwargs)
1382 estimator._validate_params()
1384 with config_context(
1385 skip_parameter_validation=(
1386 prefer_skip_nested_validation or global_skip_validation
1387 )
1388 ):
-> 1389 return fit_method(estimator, *args, **kwargs)
File ~/work/notes/notes/.venv/lib/python3.10/site-packages/sklearn/ensemble/_forest.py:487, in BaseForest.fit(self, X, y, sample_weight)
476 trees = [
477 self._make_estimator(append=False, random_state=random_state)
478 for i in range(n_more_estimators)
479 ]
481 # Parallel loop: we prefer the threading backend as the Cython code
482 # for fitting the trees is internally releasing the Python GIL
483 # making threading more efficient than multiprocessing in
484 # that case. However, for joblib 0.12+ we respect any
485 # parallel_backend contexts set at a higher level,
486 # since correctness does not rely on using threads.
--> 487 trees = Parallel(
488 n_jobs=self.n_jobs,
489 verbose=self.verbose,
490 prefer="threads",
491 )(
492 delayed(_parallel_build_trees)(
493 t,
494 self.bootstrap,
495 X,
496 y,
497 sample_weight,
498 i,
499 len(trees),
500 verbose=self.verbose,
501 class_weight=self.class_weight,
502 n_samples_bootstrap=n_samples_bootstrap,
503 missing_values_in_feature_mask=missing_values_in_feature_mask,
504 )
505 for i, t in enumerate(trees)
506 )
508 # Collect newly grown trees
509 self.estimators_.extend(trees)
File ~/work/notes/notes/.venv/lib/python3.10/site-packages/sklearn/utils/parallel.py:77, in Parallel.__call__(self, iterable)
72 config = get_config()
73 iterable_with_config = (
74 (_with_config(delayed_func, config), args, kwargs)
75 for delayed_func, args, kwargs in iterable
76 )
---> 77 return super().__call__(iterable_with_config)
File ~/work/notes/notes/.venv/lib/python3.10/site-packages/joblib/parallel.py:1986, in Parallel.__call__(self, iterable)
1984 output = self._get_sequential_output(iterable)
1985 next(output)
-> 1986 return output if self.return_generator else list(output)
1988 # Let's create an ID that uniquely identifies the current call. If the
1989 # call is interrupted early and that the same instance is immediately
1990 # reused, this id will be used to prevent workers that were
1991 # concurrently finalizing a task from the previous call to run the
1992 # callback.
1993 with self._lock:
File ~/work/notes/notes/.venv/lib/python3.10/site-packages/joblib/parallel.py:1914, in Parallel._get_sequential_output(self, iterable)
1912 self.n_dispatched_batches += 1
1913 self.n_dispatched_tasks += 1
-> 1914 res = func(*args, **kwargs)
1915 self.n_completed_tasks += 1
1916 self.print_progress()
File ~/work/notes/notes/.venv/lib/python3.10/site-packages/sklearn/utils/parallel.py:139, in _FuncWrapper.__call__(self, *args, **kwargs)
137 config = {}
138 with config_context(**config):
--> 139 return self.function(*args, **kwargs)
File ~/work/notes/notes/.venv/lib/python3.10/site-packages/sklearn/ensemble/_forest.py:189, in _parallel_build_trees(tree, bootstrap, X, y, sample_weight, tree_idx, n_trees, verbose, class_weight, n_samples_bootstrap, missing_values_in_feature_mask)
186 elif class_weight == "balanced_subsample":
187 curr_sample_weight *= compute_sample_weight("balanced", y, indices=indices)
--> 189 tree._fit(
190 X,
191 y,
192 sample_weight=curr_sample_weight,
193 check_input=False,
194 missing_values_in_feature_mask=missing_values_in_feature_mask,
195 )
196 else:
197 tree._fit(
198 X,
199 y,
(...)
202 missing_values_in_feature_mask=missing_values_in_feature_mask,
203 )
File ~/work/notes/notes/.venv/lib/python3.10/site-packages/sklearn/tree/_classes.py:361, in BaseDecisionTree._fit(self, X, y, sample_weight, check_input, missing_values_in_feature_mask)
355 raise ValueError(
356 "Number of labels=%d does not match number of samples=%d"
357 % (len(y), n_samples)
358 )
360 if sample_weight is not None:
--> 361 sample_weight = _check_sample_weight(sample_weight, X, DOUBLE)
363 if expanded_class_weight is not None:
364 if sample_weight is not None:
File ~/work/notes/notes/.venv/lib/python3.10/site-packages/sklearn/utils/validation.py:2181, in _check_sample_weight(sample_weight, X, dtype, copy, ensure_non_negative)
2179 if dtype is None:
2180 dtype = [np.float64, np.float32]
-> 2181 sample_weight = check_array(
2182 sample_weight,
2183 accept_sparse=False,
2184 ensure_2d=False,
2185 dtype=dtype,
2186 order="C",
2187 copy=copy,
2188 input_name="sample_weight",
2189 )
2190 if sample_weight.ndim != 1:
2191 raise ValueError("Sample weights must be 1D array or scalar")
File ~/work/notes/notes/.venv/lib/python3.10/site-packages/sklearn/utils/validation.py:1040, in check_array(array, accept_sparse, accept_large_sparse, dtype, order, copy, force_writeable, force_all_finite, ensure_all_finite, ensure_non_negative, ensure_2d, allow_nd, ensure_min_samples, ensure_min_features, estimator, input_name)
1038 try:
1039 warnings.simplefilter("error", ComplexWarning)
-> 1040 if dtype is not None and xp.isdtype(dtype, "integral"):
1041 # Conversion float -> int should not contain NaN or
1042 # inf (numpy#14412). We cannot use casting='safe' because
1043 # then conversion float -> int would be disallowed.
1044 array = _asarray_with_order(array, order=order, xp=xp)
1045 if xp.isdtype(array.dtype, ("real floating", "complex floating")):
File ~/work/notes/notes/.venv/lib/python3.10/site-packages/sklearn/utils/_array_api.py:443, in _NumPyAPIWrapper.isdtype(self, dtype, kind)
441 def isdtype(self, dtype, kind):
442 try:
--> 443 return isdtype(dtype, kind, xp=self)
444 except TypeError:
445 # In older versions of numpy, data types that arise from outside
446 # numpy like from a Polars Series raise a TypeError.
447 # e.g. TypeError: Cannot interpret 'Int64' as a data type.
448 # Therefore, we return False.
449 # TODO: Remove when minimum supported version of numpy is >= 1.21.
450 return False
File ~/work/notes/notes/.venv/lib/python3.10/site-packages/sklearn/utils/_array_api.py:234, in isdtype(dtype, kind, xp)
232 return any(_isdtype_single(dtype, k, xp=xp) for k in kind)
233 else:
--> 234 return _isdtype_single(dtype, kind, xp=xp)
File ~/work/notes/notes/.venv/lib/python3.10/site-packages/sklearn/utils/_array_api.py:246, in _isdtype_single(dtype, kind, xp)
244 return dtype in {xp.uint8, xp.uint16, xp.uint32, xp.uint64}
245 elif kind == "integral":
--> 246 return any(
247 _isdtype_single(dtype, k, xp=xp)
248 for k in ("signed integer", "unsigned integer")
249 )
250 elif kind == "real floating":
251 return dtype in supported_float_dtypes(xp)
File ~/work/notes/notes/.venv/lib/python3.10/site-packages/sklearn/utils/_array_api.py:247, in <genexpr>(.0)
244 return dtype in {xp.uint8, xp.uint16, xp.uint32, xp.uint64}
245 elif kind == "integral":
246 return any(
--> 247 _isdtype_single(dtype, k, xp=xp)
248 for k in ("signed integer", "unsigned integer")
249 )
250 elif kind == "real floating":
251 return dtype in supported_float_dtypes(xp)
File ~/work/notes/notes/.venv/lib/python3.10/site-packages/sklearn/utils/_array_api.py:242, in _isdtype_single(dtype, kind, xp)
240 return dtype == xp.bool
241 elif kind == "signed integer":
--> 242 return dtype in {xp.int8, xp.int16, xp.int32, xp.int64}
243 elif kind == "unsigned integer":
244 return dtype in {xp.uint8, xp.uint16, xp.uint32, xp.uint64}
File ~/work/notes/notes/.venv/lib/python3.10/site-packages/sklearn/utils/_array_api.py:381, in _NumPyAPIWrapper.__getattr__(self, name)
361 # Data types in spec
362 # https://data-apis.org/array-api/latest/API_specification/data_types.html
363 _DTYPES = {
364 "int8",
365 "int16",
(...)
378 "complex128",
379 }
--> 381 def __getattr__(self, name):
382 attr = getattr(numpy, name)
384 # Support device kwargs and make sure they are on the CPU
KeyboardInterrupt:
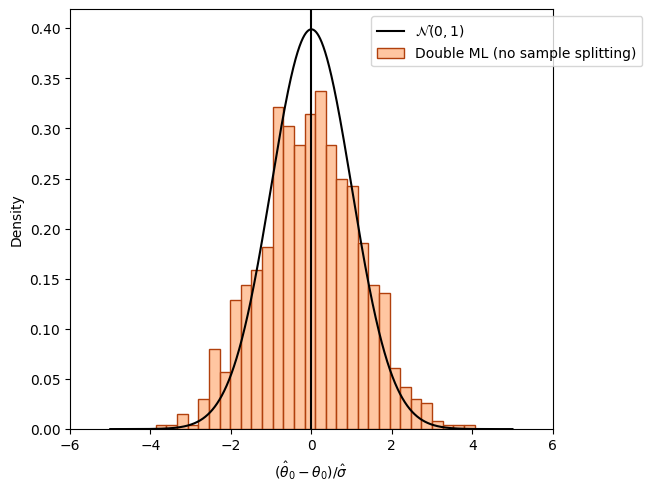
Overcoming regularization bias by orthogonalization#
orthogonalized regressor \(V=D-m(X)\)を用いる推定量
\[
\check{\theta}_0 = \left(\frac{1}{n} \sum_{i\in I} \hat{V}_i D_i\right)^{-1} \frac{1}{n} \sum_{i\in I} \hat{V}_i (Y_i - \hat{g}_0(X_i)).
\]
np.random.seed(2222)
theta_orth_nosplit = np.full(n_rep, np.nan)
se_orth_nosplit = np.full(n_rep, np.nan)
for i_rep in range(n_rep):
print(f'Replication {i_rep+1}/{n_rep}', end='\r')
(x, y, d) = data[i_rep]
# fit the ML algorithms on the training sample
ml_l.fit(x, y)
ml_m.fit(x, d)
psi_a = -np.multiply(d - ml_m.predict(x), d - ml_m.predict(x))
psi_b = np.multiply(d - ml_m.predict(x), y - ml_l.predict(x))
theta_initial = -np.nanmean(psi_b) / np.nanmean(psi_a)
ml_g.fit(x, y - theta_initial * d)
l_hat = ml_l.predict(x)
m_hat = ml_m.predict(x)
g_hat = ml_g.predict(x)
external_predictions = {
'd': {
'ml_l': l_hat.reshape(-1, 1),
'ml_m': m_hat.reshape(-1, 1),
'ml_g': g_hat.reshape(-1, 1)
}
}
obj_dml_data = DoubleMLData.from_arrays(x, y, d)
obj_dml_plr_orth_nosplit = DoubleMLPLR(obj_dml_data,
ml_l, ml_m, ml_g,
score='IV-type')
obj_dml_plr_orth_nosplit.fit(external_predictions=external_predictions)
theta_orth_nosplit[i_rep] = obj_dml_plr_orth_nosplit.coef[0]
se_orth_nosplit[i_rep] = obj_dml_plr_orth_nosplit.se[0]
fig_orth_nosplit, ax = plt.subplots(constrained_layout=True);
ax = sns.histplot((theta_orth_nosplit - alpha)/se_orth_nosplit,
color=face_colors[1], edgecolor = edge_colors[1],
stat='density', bins=30, label='Double ML (no sample splitting)');
ax.axvline(0., color='k');
xx = np.arange(-5, +5, 0.001)
yy = stats.norm.pdf(xx)
ax.plot(xx, yy, color='k', label='$\\mathcal{N}(0, 1)$');
ax.legend(loc='upper right', bbox_to_anchor=(1.2, 1.0));
ax.set_xlim([-6., 6.]);
ax.set_xlabel('$(\hat{\\theta}_0 - \\theta_0)/\hat{\sigma}$');
plt.show()
Replication 1000/1000
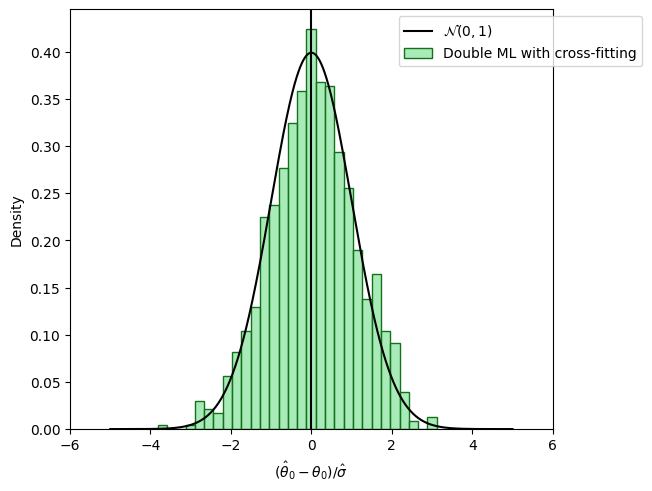
Sample splitting to remove bias induced by overfitting#
np.random.seed(3333)
theta_dml = np.full(n_rep, np.nan)
se_dml = np.full(n_rep, np.nan)
for i_rep in range(n_rep):
print(f'Replication {i_rep+1}/{n_rep}', end='\r')
(x, y, d) = data[i_rep]
obj_dml_data = DoubleMLData.from_arrays(x, y, d)
obj_dml_plr = DoubleMLPLR(obj_dml_data,
ml_l, ml_m, ml_g,
n_folds=2,
score='IV-type')
obj_dml_plr.fit()
theta_dml[i_rep] = obj_dml_plr.coef[0]
se_dml[i_rep] = obj_dml_plr.se[0]
fig_dml, ax = plt.subplots(constrained_layout=True);
ax = sns.histplot((theta_dml - alpha)/se_dml,
color=face_colors[2], edgecolor = edge_colors[2],
stat='density', bins=30, label='Double ML with cross-fitting');
ax.axvline(0., color='k');
xx = np.arange(-5, +5, 0.001)
yy = stats.norm.pdf(xx)
ax.plot(xx, yy, color='k', label='$\\mathcal{N}(0, 1)$');
ax.legend(loc='upper right', bbox_to_anchor=(1.2, 1.0));
ax.set_xlim([-6., 6.]);
ax.set_xlabel('$(\hat{\\theta}_0 - \\theta_0)/\hat{\sigma}$');
plt.show()
Replication 1000/1000