GESアルゴリズム#
Greedy Equivalence Search (GES) アルゴリズムはBIC(Bayesian Information Criterion)などのスコアを最大化する貪欲探索により DAG を求める手法。
エッジを追加したり削除したりしつつ最大のスコアとなるグラフを探索する。
前向き段階(Forward Phase)
スコアが最も良くなるように エッジを追加していく
後向き段階(Backward Phase)
スコアが最も良くなるように エッジを削除していく




スコア#
BIC#
\[
BIC = -2\ell(\hat{\theta}) + k\log n
\]
ここで
\(n\):サンプルサイズ
\(k\):モデルのパラメータ数
\(\ell(\hat{\theta})\):最尤推定したときの対数尤度
from castle.common import GraphDAG
from castle.metrics import MetricsDAG
from castle.datasets import load_dataset
from castle.algorithms import GES
X, true_dag, _ = load_dataset(name='IID_Test')
algo = GES()
algo.learn(X)
# plot DAG
GraphDAG(algo.causal_matrix, true_dag)
# calc Metrics
met = MetricsDAG(algo.causal_matrix, true_dag)
print(met.metrics)
INFO:root:Finished synthetic dataset
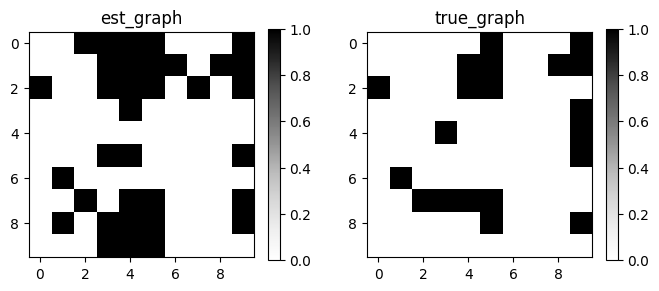
{'fdr': 0.3824, 'tpr': 1.05, 'fpr': 0.52, 'shd': 14, 'nnz': 34, 'precision': 0.4706, 'recall': 0.8, 'F1': 0.5926, 'gscore': 0.0}
実装#
Greedy Equivalence Search (GES) — 1.0.0 | pgmpy docs
# データセットの生成
import numpy as np
from pgmpy.utils import get_example_model
np.random.seed(42)
model = get_example_model("asia")
model.seed = 42
df = model.simulate(int(1e3))
# 因果構造を推定
from pgmpy.estimators import GES
est = GES(df)
dag = est.estimate(scoring_method="bic-d")
# daftパッケージで作図
dag.to_daft().render()
INFO:pgmpy: Datatype (N=numerical, C=Categorical Unordered, O=Categorical Ordered) inferred from data:
{'asia': 'C', 'xray': 'C', 'either': 'C', 'dysp': 'C', 'tub': 'C', 'smoke': 'C', 'bronc': 'C', 'lung': 'C'}
INFO:pgmpy: Datatype (N=numerical, C=Categorical Unordered, O=Categorical Ordered) inferred from data:
{'asia': 'C', 'xray': 'C', 'either': 'C', 'dysp': 'C', 'tub': 'C', 'smoke': 'C', 'bronc': 'C', 'lung': 'C'}
INFO:pgmpy: Datatype (N=numerical, C=Categorical Unordered, O=Categorical Ordered) inferred from data:
{'asia': 'C', 'xray': 'C', 'either': 'C', 'dysp': 'C', 'tub': 'C', 'smoke': 'C', 'bronc': 'C', 'lung': 'C'}
<Axes: >
