PCアルゴリズム#
Peter-Clark (PC) algorithm
Step1:すべてのノード間が無向のエッジで結ばれたグラフを作る

Step 2:条件付き独立性を検定し、不要なエッジの削除
独立性や条件付き独立性をカイ二乗検定で判定していく。 \(X_i \perp X_j\) または \(X_i \perp X_j \mid S\) が統計的に判定できた場合、そのエッジを削除し、分離集合(separating set)\(S\) を記録する。
例:\(X_1 \perp X_3 \mid X_2\) が成立 → 辺 X1–X3 を削除、sep(X1,X3) = {X2}

Step 3:V-構造(Collider)の同定
3変数 \(X_i - X_j - X_k\) のパターンで、
\(X_i\) と \(X_k\) が「隣接していない」(エッジがない、\(X_i \perp X_k \mid S\))
その分離集合 sep(\(X_i, X_k\)) に \(X_j\) が含まれない(\(X_j \notin S\))
のとき、\(X_i \rightarrow X_j \leftarrow X_k\)(V構造、collider) と向きを付ける。

Step 4:向き付け規則(Orientation Rules)で残りの辺を決める
追加のルールを適用し、サイクルを作らない・新たな collider を作らないように残りの無向辺に向きを付ける。
代表的ルール:
Orientation propagation:\(X \to Y - Z\) なら \(Y \to Z\)
Acyclicity constraint(サイクル禁止)
Avoid new colliders(既存以外の新規 collider を作らない)

限界・注意点#
PCアルゴリズムは以下の点に注意が必要
1️⃣すべての変数間の因果の方向が定まらないことがある
同じ条件付き独立性を与える因果グラフの集合を マルコフ同値類(Markov equivalence class: MEC) という。
PCアルゴリズムではMECの中から因果グラフを一意に特定できない場合がある。
2️⃣サンプルサイズが必要
サンプルサイズが小さい場合はカイ二乗分布を用いた近似精度が悪化するため、適切に検定できなくなる
3️⃣高次元データに弱い
PCアルゴリズムは条件付き独立性の検定を実施する順番に影響されやすい。そのため次元数が多いと推定が不安定になりやすい。 これを改善したPC-stableというアルゴリズムもある。
4️⃣未観測の交絡因子と選択バイアスが考慮されていない
因果的十分性の仮定をおいているため、この仮定が満たされない場合は因果探索の推定精度が下がる。
この点を改良したFCIアルゴリズムが提案されている。
5️⃣検定の有意水準の設定によって推定結果が変わる
6️⃣計算量が多い
すべての変数の組み合わせに対して統計的検定を行うため、変数の数が多いと処理しきれない
実装#
from castle.common import GraphDAG
from castle.metrics import MetricsDAG
from castle.datasets import IIDSimulation, DAG
from castle.algorithms import PC
# シミュレーションデータの生成
weighted_random_dag = DAG.erdos_renyi(n_nodes=10, n_edges=10,
weight_range=(0.5, 2.0), seed=1)
dataset = IIDSimulation(W=weighted_random_dag, n=2000, method='linear',
sem_type='gauss')
true_causal_matrix, X = dataset.B, dataset.X
# structure learning
pc = PC()
pc.learn(X)
# DAGをmatrixとしてplot
GraphDAG(pc.causal_matrix, true_causal_matrix)
# metricsを計算
mt = MetricsDAG(pc.causal_matrix, true_causal_matrix)
print(mt.metrics)
2026-06-21 23:17:54,548 - /home/runner/work/notes/notes/.venv/lib/python3.10/site-packages/castle/backend/__init__.py[line:36] - INFO: You can use `os.environ['CASTLE_BACKEND'] = backend` to set the backend(`pytorch` or `mindspore`).
2026-06-21 23:17:54,593 - /home/runner/work/notes/notes/.venv/lib/python3.10/site-packages/castle/algorithms/__init__.py[line:36] - INFO: You are using ``pytorch`` as the backend.
2026-06-21 23:17:54,597 - /home/runner/work/notes/notes/.venv/lib/python3.10/site-packages/castle/datasets/simulator.py[line:270] - INFO: Finished synthetic dataset
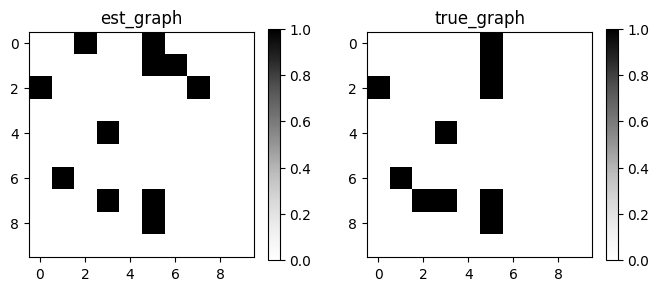
{'fdr': 0.0909, 'tpr': 1.0, 'fpr': 0.0286, 'shd': 2, 'nnz': 11, 'precision': 0.7273, 'recall': 0.8, 'F1': 0.7619, 'gscore': 0.5}
実装#
pgmpyパッケージ
# データセットの生成
import numpy as np
from pgmpy.utils import get_example_model
np.random.seed(42)
model = get_example_model("asia")
model.seed = 42
df = model.simulate(int(1e3))
# 因果構造を推定
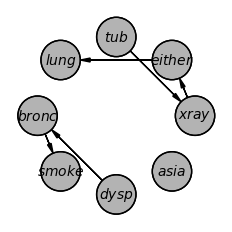
from pgmpy.estimators import PC
dag = PC(data=df).estimate(ci_test='chi_square', return_type='dag')
# daftパッケージで作図
dag.to_daft().render()
# データセットの生成
import numpy as np
from pgmpy.utils import get_example_model
np.random.seed(42)
model = get_example_model("asia")
model.seed = 42
df = model.simulate(int(1e3))
# 因果構造を推定
from pgmpy.estimators import PC
dag = PC(data=df).estimate(ci_test='chi_square', return_type='dag')
# daftパッケージで作図
dag.to_daft().render()
2026-06-21 23:17:57,432 - /home/runner/work/notes/notes/.venv/lib/python3.10/site-packages/pgmpy/utils/utils.py[line:402] - INFO: Datatype (N=numerical, C=Categorical Unordered, O=Categorical Ordered) inferred from data:
{'xray': 'C', 'smoke': 'C', 'dysp': 'C', 'lung': 'C', 'either': 'C', 'bronc': 'C', 'tub': 'C', 'asia': 'C'}
<Axes: >