独立成分分析#
独立成分分析(ICA: Independent Component Analysis) は、独立成分分析(ICA)とは、 観測信号を「互いに統計的に独立な成分」に分解する手法 である。
代表的な例として「カクテルパーティ問題」があり、複数のマイクに混ざって届いた音声から、話者ごとの音声を分離する問題として知られている。 また、統計的因果探索のLiNGAMでも用いられている。
主成分分析(PCA)が「無相関な成分」への回転であるのに対し、ICA はより強い “独立性” を基準に回転を求める点に特徴がある。
目的#
観測されたベクトル \(x\)(混合信号)を \(x = A s\) と分解し、
\(A\):混合行列
\(s\):互いに独立な信号(独立成分)
を推定することが ICA の目的。
ここで \(s\) は統計的に独立であること が仮定される。
モデル#
ICA は混合モデルを前提とする。
\(x \in \mathbb{R}^d\):観測信号
\(s\in \mathbb{R}^d\):独立成分(未知)
\(A\):正則な混合行列(未知)
ICA の目標は 復元行列\(W = A^{-1}\) を求めて \(s = Wx\) を得て信号\(s\)を求める こと。
ICA が成立するためには次の性質が重要となる。
ICAの仮定#
ICA が識別可能であるためには、以下が必要:
独立成分のうち少なくとも一つは非ガウス
ガウス成分のみの場合、どんな直交回転をしても不変であるため識別不能。
混合が線形
基本 ICA は線形混合を仮定する(非線形 ICA は別途理論が必要)。
\(A\) が可逆
非可逆だと \(s\) が一意に復元できない。
ICA の解法の考え方#
ICA では 独立性を最大にする方向(回転)を求めることが本質である。
代表的なアプローチには以下のものがある
非ガウス性の最大化(FastICA)#
独立成分は非ガウス性が強いので、
尖度(kurtosis)
negentropy(ネゲントロピー)
を最大化する方向を探す。
FastICA の代表的更新式は
であり、反復により \(w\) を収束させる。
相互情報量(Mutual Information)の最小化(Infomax)#
独立性の尺度として、
相互情報量 \(I(s_1,\dots,s_d)\) を最小化する方法がある。
独立であれば相互情報量は 0。
最大尤度法(ML)#
混合モデル \(x = As\) の尤度を最大化するアプローチも存在する。
Pythonでの実装#
scikit-learnにはFastICAなどの高速なアルゴリズムが実装されている
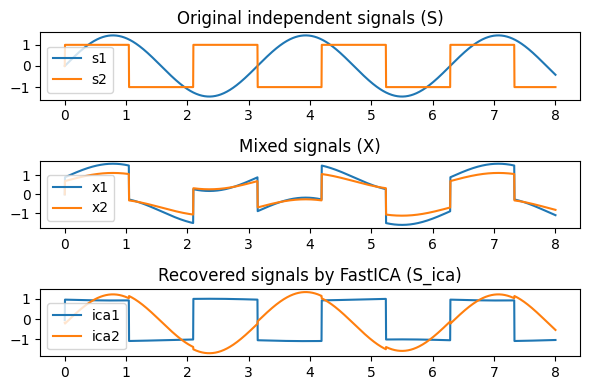
Aの推定#
混合行列\(A\)の推定結果
予測値:
[[0.53 0.93]
[0.32 0.72]]
真値:
[[0.5 0.9]
[0.3 0.7]]