損失関数#
回帰 Regression#
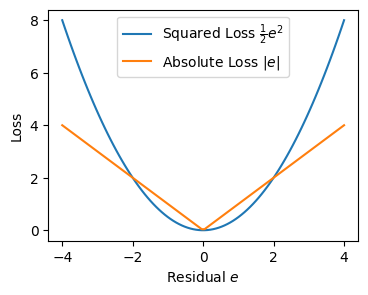
二乗損失#
二乗損失 (Squared Loss)
観測値 \(y\)、予測値 \(\hat y\)、残差 \(e = y - \hat y\) とおくと
誤差を二乗するので、絶対誤差に比べて大きく予測を外した値が強調されるのが特徴。
\(\frac{1}{2}\)を乗じているのは微分したときに簡潔に示すため。
絶対損失#
二乗しないため外れ値に強い(外れ値の予測誤差を比較的小さく評価する)。
絶対損失 (Absolute Loss)
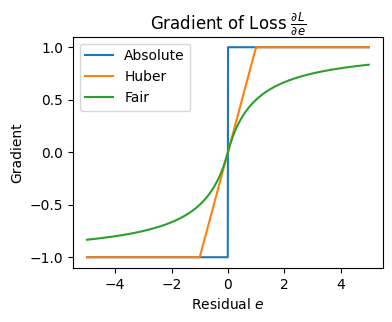
勾配
\(e = 0\) では微分が定義されないため、劣勾配(subgradient) として区間 \([-1, 1]\) を取る
実装上は多くの場合、\(\frac{\partial L}{\partial e} = \mathrm{sign}(e)\) とし、\(e = 0\) の場合は \(0\) を返すことが多い
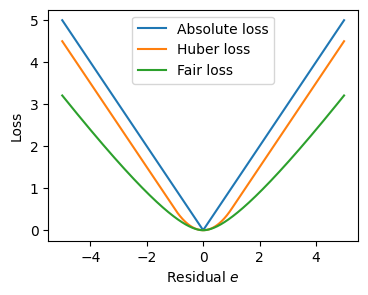
Huber Loss#
絶対損失がゼロ付近で微分不可能である問題に対処し、ある閾値\(\delta\)未満の誤差( \(|e| \le \delta\) )のときだけ二乗損失にしたもの。
Huber Loss
観測値 \(y\)、予測値 \(\hat y\)、残差 \(e = y - \hat y\)、しきい値 \(\delta > 0\) とすると、
勾配
Fair loss#
Fair loss は、残差が大きくなるにつれて影響を連続的になだらかに抑制するロバスト損失関数である。
Huber loss のような明確な折れ点を持たず、全域で滑らかな形状を持つ。
Fair Loss
スケールパラメータ \(c > 0\)、残差 \(e = y - \hat y\) とすると、
勾配
特徴
小さな残差では二乗誤差に近い挙動
残差が大きくなるにつれて勾配が連続的に減衰
全域で滑らか(高階微分も連続)
非常に大きな外れ値に対しても安定
利用場面
外れ値が多い、または裾の重い分布を持つデータ
勾配ベース最適化で数値安定性を重視する場合
Huber loss よりも強いロバスト性が必要なケース
MAPEの最適化にFair Loss
MAPEは絶対誤差(MAE)に似ているが、絶対損失だと勾配をとったときに残差の符号しか残らず、誤差の大きさがわからなくなる。
その点、Fair Lossのほうがいいらしい。
(参考:SIGNATE 土地価格コンペ 1位解法)
確率予測#
Log Loss(Cross Entropy Loss)#
予測確率の信頼度を含めた誤差指標。確率出力モデルに適する。