Chatterjee’s \(\xi\)#
概要#
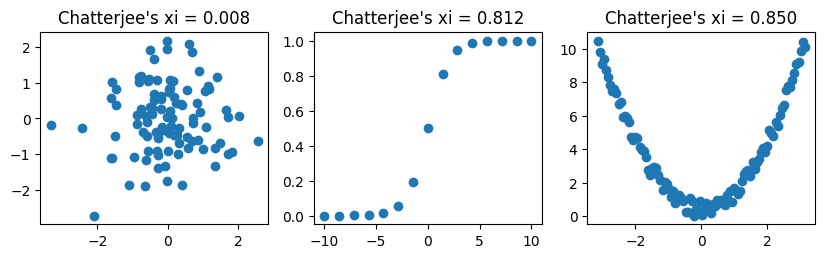
Chatterjee (2021) によって提案された ξ(xi)相関係数 は、
あらゆる形の依存関係(線形・非線形)に対して感度が高い
ノンパラメトリックで順位に基づく
\(X\) の分布に依存しない(一様性の仮定が不要)
計算量が \(O(n \log n)\) と高速(先行研究のMICは遅い)
という特徴を持つ新しい相関係数である。
目的は、「\(Y\) が \(X\) にどれだけ依存しているか」を測ることであり、特に回帰関係一般に対する依存度測定として利用できる。
アルゴリズム#
\((X, Y)\)を確率変数のペアとし、\(n\geq 2\)のiidな標本があるとする。
Step 1. データの並び替え#
データ \((X_{(1)}, Y_{(1)}), \ldots,(X_{(n)}, Y_{(n)})\) を \(X\) で昇順 \(X_{(1)} \leq \cdots \leq X_{(n)}\) に並べ替える。
同値がいれば一様にランダムに選ぶ。
Step 2. 相関係数\(\xi_n\)を計算する#
\(Y_{(j)} \leq Y_{(i)}\)の\(j\)、すなわち\(Y_{(i)}\)の順位を\(r_i\)とする。
\(Y_{(j)} \geq Y_{(i)}\)の\(j\)、すなわち\(Y_{(i)}\)の逆順位を\(l_i\)とする。
同順位がいない場合:
同順位がいる場合:
性質#
定理 1.1
もし \(Y\) がほとんど確実に定数でないなら、\(n \to \infty\) のとき、\(\xi_n(X, Y)\) はほとんど確実に次の決定論的極限に収束する:
ただし \(\mu\) は \(Y\) の分布である。この極限は区間 \([0, 1]\) に属する。
\(X\) と \(Y\) が独立であることと、\(\xi(X, Y) = 0\) は同値である。
また、\(\xi(X, Y) = 1\) であることと、ある可測関数 \(f : \mathbb{R} \to \mathbb{R}\) が存在して\(Y = f(X)\) がほとんど確実に成り立つことは同値である。
「\(Y = f(X)\) という関係のとき \(\xi(X, Y) = 1\) になる」という性質・コンセプトが他の相関係数とは異なる。
対称性はない
多くの相関係数とは異なり、\(\xi_n\) は \(X\) と \(Y\) の順序に対して対称ではない(すなわち \(\xi_n(X, Y) \ne \xi_n(Y, X)\) の可能性がある)。
目的として、単に「二つの変数のどちらかが他方の関数か」を知りたいのではなく、「\(Y\) が \(X\) の関数か」を知りたいため、この性質は意図的なものである。もし「\(X\) が \(Y\) の関数か」を知りたいのであれば、\(\xi_n(Y, X)\) を用いればよい。
また、対称な依存度の尺度が必要であれば、\(\xi_n(X, Y)\) と \(\xi_n(Y, X)\) の最大値を取ればよい。対称化された係数は確率収束により \(\max\{\xi(X, Y), \xi(Y, X)\}\) に収束するが、これは「独立なら 0」、「少なくとも一方が他方の可測関数なら 1」である。
実装#
scipyに実装されている
chatterjeexi — SciPy v1.16.2 Manual
from scipy.stats import chatterjee
xi = chatterjee(x, y)
import numpy as np
from scipy.stats import rankdata
def chatterjee_xi(x, y):
"""
Compute Chatterjee (2021) xi correlation.
"""
x = np.asarray(x)
y = np.asarray(y)
n = x.size
# --- Step 1: Sort pairs by X (X(1),...,X(n)) ---
idx = np.argsort(x)
y_sorted = y[idx]
# --- Step 2: r_i, l_i (rank and reverse rank of Y(i)) ---
r = rankdata(y_sorted, method="max") # r_i = rank(Y(i))
l = rankdata(-y_sorted, method="max") # l_i = reverse rank = rank(-Y(i))
# --- Step 3: num = Σ|r_{i+1} - r_i| ---
num = np.sum(np.abs(np.diff(r)))
# --- Step 4: xi_n ---
has_tie = all(x != np.unique(x)) or all(y != np.unique(y))
if has_tie:
den = np.sum((n - l) * l)
xi = 1 - n * num / (2 * den)
else:
xi = 1 - 3 * num / (n**2 - 1)
return xi
参考#
Sourav Chatterjee (2021) A New Coefficient of Correlation, Journal of theAmerican Statistical Association, 116:536, 2009-2022 https://doi.org/10.1080/01621459.2020.1758115