段階反応モデル#
段階反応モデル(graded response model: GRM, Samejima, 1969) は多値の順序尺度の反応を扱えるモデル。複数の二値IRTモデルを組み合わせて多値反応を表現する。
回答者\(i\)の項目\(j\)に対する回答\(y_{ij} = k \ (k=1,2,\dots,K)\)について、「\(k\)以上のカテゴリを選ぶ確率」を考えると、これはまだ「\(k\)未満 or \(k\)以上」の二値なので2PLなどで表せる。例えば以下のようになる。
なお、困難度は項目\(j\)のカテゴリ\(k\)ごとに用意されるため\(b_{jk}\)に変更している。
このモデルを組み合わせると、「ちょうど\(k\)番目のカテゴリを選ぶ確率」は
と表すことができる。ただし端のカテゴリは\(P(y_{ij} \geq 1) = 1, P(y_{ij} \geq K + 1) = 0\)とする。また確率100%の困難度は低くて当然なので\(b_{j1} = -\infty\)とする。
段階反応モデル
実装例(全項目のカテゴリ数が等しい場合)#
PyMCパッケージを使ってベイズ推定する場合、各項目のカテゴリ数が同じ場合は順序ロジットモデルで簡単に実装できる
# データを生成
import numpy as np
import pandas as pd
def simulate_grm(N=1000, J=10, K=4, seed=42):
rng = np.random.default_rng(seed)
theta = rng.normal(0, 1, size=N)
a = rng.lognormal(0, 0.3, size=J)
b = np.sort(
rng.normal(0, 1, size=(J, K-1)),
axis=1
)
U = np.zeros((N, J), dtype=int)
for j in range(J):
for i in range(N):
eta = a[j]*(theta[i] - b[j])
P_ge = 1 / (1 + np.exp(-eta))
P = np.empty(K)
P[0] = 1 - P_ge[0]
for k in range(1, K-1):
P[k] = P_ge[k-1] - P_ge[k]
P[K-1] = P_ge[K-2]
U[i, j] = rng.choice(K, p=P)
return U, theta, a, b
num_users = 1000
num_items = 20
U, true_theta, true_a, true_b = simulate_grm(N=num_users, J=num_items)
df = pd.DataFrame(U,
index=[f"user_{i+1}" for i in range(num_users)],
columns=[f"item_{j+1}" for j in range(num_items)])
df.head()
| item_1 | item_2 | item_3 | item_4 | item_5 | item_6 | item_7 | item_8 | item_9 | item_10 | item_11 | item_12 | item_13 | item_14 | item_15 | item_16 | item_17 | item_18 | item_19 | item_20 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| user_1 | 0 | 3 | 3 | 0 | 3 | 3 | 3 | 3 | 3 | 1 | 3 | 1 | 3 | 0 | 2 | 1 | 3 | 0 | 0 | 1 |
| user_2 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 3 | 0 | 1 | 0 | 3 | 0 | 0 | 0 | 0 | 1 | 0 |
| user_3 | 3 | 0 | 3 | 3 | 3 | 0 | 3 | 0 | 3 | 3 | 2 | 1 | 3 | 0 | 3 | 3 | 0 | 1 | 1 | 0 |
| user_4 | 0 | 1 | 1 | 1 | 0 | 3 | 1 | 1 | 3 | 3 | 3 | 1 | 3 | 3 | 2 | 3 | 3 | 3 | 3 | 1 |
| user_5 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 2 | 0 | 1 | 0 | 0 | 0 | 0 | 2 | 0 | 2 | 0 | 0 |
# 縦持ちへ変換
user_categories = df.index
item_categories = df.columns
df_long = pd.melt(
df.reset_index(),
id_vars="index",
var_name="item",
value_name="response",
).rename(columns={"index": "user"})
df_long["user"] = pd.Categorical(df_long["user"], categories=user_categories, ordered=True)
df_long["item"] = pd.Categorical(df_long["item"], categories=item_categories, ordered=True)
df_long.head()
| user | item | response | |
|---|---|---|---|
| 0 | user_1 | item_1 | 0 |
| 1 | user_2 | item_1 | 0 |
| 2 | user_3 | item_1 | 3 |
| 3 | user_4 | item_1 | 0 |
| 4 | user_5 | item_1 | 0 |
閾値(cutpoints)の推定#
pymc.OrderedLogistic が \(\text{logit}^{-1}(\eta - c_k)\) なので、IRTモデルの\(\text{logit}^{-1}(a(\theta - b_k)) = \text{logit}^{-1}(a\theta - a b_k)\) に合わせると cutpoints = a[:, None] * b のようにするのが素直な実装。
# --- GRM の閾値:各 item ごとに (K-1) 本 ---
# ordered transform が last axis に対して単調増加を強制する想定
b = pm.Normal(
"b",
mu=np.linspace(-1, 1, n_thresholds),
sigma=2.0,
dims=("item", "threshold"),
initval=np.tile(np.linspace(-1, 1, n_thresholds), (num_items, 1)), # 初期値を指定
transform=pm.distributions.transforms.ordered,
)
# GRM の cutpoints: a_j * b_{jk}
# OrderedLogistic は P(Y >= k) = sigma(eta - cutpoints_k) を計算するため、
# Samejima のパラメタリゼーション P(Y >= k) = sigma(a*(theta - b)) に合わせるには
# cutpoints = a * b とする必要がある(a > 0 なので順序は保たれる)
cutpoints = a[:, None] * b
しかし、これはaとbに依存が関係が生じてサンプリングが安定しにくいかもしれない。cutpoints = pm.Normal() にして b = cutpoints / a[:, None] としたほうが良いかも
import numpy as np
import pymc as pm
# indexと値の取得
user_idx = df_long["user"].cat.codes.to_numpy()
users = df_long["user"].cat.categories.to_numpy()
item_idx = df_long["item"].cat.codes.to_numpy()
items = df_long["item"].cat.categories.to_numpy()
responses = df_long["response"].to_numpy().astype("int64") # 0..K-1
# カテゴリ数
K = int(responses.max() + 1)
n_thresholds = K - 1
coords = {
"user": users,
"item": items,
"threshold": np.arange(n_thresholds),
"obs_id": np.arange(len(df_long)),
}
with pm.Model(coords=coords) as model:
responses_ = pm.Data("responses", responses, dims="obs_id")
theta = pm.Normal("theta", 0.0, 1.0, dims="user")
a = pm.LogNormal("a", 0.0, 0.5, dims="item")
# --- 閾値:各 item ごとに (K-1) 本 ---
b = pm.Normal(
"b",
mu=np.linspace(-1, 1, n_thresholds),
sigma=2.0,
dims=("item", "threshold"),
initval=np.tile(np.linspace(-1, 1, n_thresholds), (num_items, 1)), # 初期値を指定
transform=pm.distributions.transforms.ordered,
)
# OrderedLogistic は P(Y >= k) = inv_logit(eta - cutpoints_k) を計算するため、
# GRM の P(Y >= k) = inv_logit(a*(theta - b_k)) に合わせてcutpoints_k = a * b_k
cutpoints = pm.Deterministic("cutpoints", a[:, None] * b)
# 線形予測子
eta = pm.Deterministic("eta", a[item_idx] * theta[user_idx])
# 観測:item ごとの cutpoints を観測ごとに参照
pm.OrderedLogistic(
"obs",
eta=eta,
cutpoints=cutpoints[item_idx],
observed=responses_,
dims="obs_id",
)
pm.model_to_graphviz(model)

推定#
%%time
with model:
idata = pm.sample(random_seed=0, draws=1000, tune=2000)
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (2 chains in 2 jobs)
NUTS: [theta, a, b]
---------------------------------------------------------------------------
ValueError Traceback (most recent call last)
File <timed exec>:2
File ~/work/notes/notes/.venv/lib/python3.10/site-packages/pymc/sampling/mcmc.py:957, in sample(draws, tune, chains, cores, random_seed, progressbar, progressbar_theme, step, var_names, nuts_sampler, initvals, init, jitter_max_retries, n_init, trace, discard_tuned_samples, compute_convergence_checks, keep_warning_stat, return_inferencedata, idata_kwargs, nuts_sampler_kwargs, callback, mp_ctx, blas_cores, model, compile_kwargs, **kwargs)
953 t_sampling = time.time() - t_start
955 # Packaging, validating and returning the result was extracted
956 # into a function to make it easier to test and refactor.
--> 957 return _sample_return(
958 run=run,
959 traces=trace if isinstance(trace, ZarrTrace) else traces,
960 tune=tune,
961 t_sampling=t_sampling,
962 discard_tuned_samples=discard_tuned_samples,
963 compute_convergence_checks=compute_convergence_checks,
964 return_inferencedata=return_inferencedata,
965 keep_warning_stat=keep_warning_stat,
966 idata_kwargs=idata_kwargs or {},
967 model=model,
968 )
File ~/work/notes/notes/.venv/lib/python3.10/site-packages/pymc/sampling/mcmc.py:1042, in _sample_return(run, traces, tune, t_sampling, discard_tuned_samples, compute_convergence_checks, return_inferencedata, keep_warning_stat, idata_kwargs, model)
1040 # Pick and slice chains to keep the maximum number of samples
1041 if discard_tuned_samples:
-> 1042 traces, length = _choose_chains(traces, tune)
1043 else:
1044 traces, length = _choose_chains(traces, 0)
File ~/work/notes/notes/.venv/lib/python3.10/site-packages/pymc/backends/base.py:624, in _choose_chains(traces, tune)
622 lengths = [max(0, len(trace) - tune) for trace in traces]
623 if not sum(lengths):
--> 624 raise ValueError("Not enough samples to build a trace.")
626 idxs = np.argsort(lengths)
627 l_sort = np.array(lengths)[idxs]
ValueError: Not enough samples to build a trace.
EAP推定量#
import arviz as az
az.summary(idata, var_names=["a", "b"], round_to=2)
| mean | sd | hdi_3% | hdi_97% | mcse_mean | mcse_sd | ess_bulk | ess_tail | r_hat | |
|---|---|---|---|---|---|---|---|---|---|
| a[item_1] | 0.94 | 0.09 | 0.77 | 1.12 | 0.0 | 0.0 | 2406.78 | 2928.07 | 1.00 |
| a[item_2] | 0.75 | 0.07 | 0.62 | 0.89 | 0.0 | 0.0 | 1172.53 | 1324.90 | 1.00 |
| a[item_3] | 0.90 | 0.08 | 0.75 | 1.05 | 0.0 | 0.0 | 1331.70 | 2025.87 | 1.00 |
| a[item_4] | 1.13 | 0.10 | 0.96 | 1.31 | 0.0 | 0.0 | 2135.03 | 2944.66 | 1.00 |
| a[item_5] | 0.88 | 0.08 | 0.74 | 1.05 | 0.0 | 0.0 | 1712.02 | 2359.38 | 1.01 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| b[item_19, 1] | 0.12 | 0.08 | -0.04 | 0.26 | 0.0 | 0.0 | 2724.39 | 3421.61 | 1.00 |
| b[item_19, 2] | 1.30 | 0.13 | 1.05 | 1.55 | 0.0 | 0.0 | 1597.53 | 2120.53 | 1.00 |
| b[item_20, 0] | -0.64 | 0.08 | -0.78 | -0.50 | 0.0 | 0.0 | 1336.95 | 2396.03 | 1.00 |
| b[item_20, 1] | 1.38 | 0.11 | 1.18 | 1.58 | 0.0 | 0.0 | 2044.45 | 2471.56 | 1.00 |
| b[item_20, 2] | 2.64 | 0.18 | 2.32 | 3.00 | 0.0 | 0.0 | 1817.68 | 2467.32 | 1.00 |
80 rows × 9 columns
post_mean = idata.posterior.mean(dim=["chain", "draw"])
# 項目パラメータのEAP推定量
params_EAP = pd.DataFrame({
"item": coords["item"],
"a": post_mean["a"],
})
params_EAP.head()
| item | a | |
|---|---|---|
| 0 | item_1 | 0.944434 |
| 1 | item_2 | 0.751282 |
| 2 | item_3 | 0.898166 |
| 3 | item_4 | 1.134108 |
| 4 | item_5 | 0.884190 |
実装例(各項目のカテゴリ数が異なる場合)#
OrderedLogisticを複数個重ねるように実装する方法がある
rng = np.random.default_rng(42)
N = 100 # respondents
J = 20 # items total
# K per item
K_per_item = np.array([3] * 7 + [4] * 7 + [5] * 6)
# True parameters
theta_true = rng.normal(0, 1, N)
a_true = rng.lognormal(0, 0.5, J)
# b_true[j]: sorted array of K_j-1 thresholds
b_true = [np.sort(rng.normal(0, 1, K_per_item[j] - 1)) for j in range(J)]
# Generate responses
Y = np.zeros((N, J), dtype=int)
for j in range(J):
K_j = K_per_item[j]
# P*(Y >= k) for k=1,...,K_j-1 — shape (N, K_j-1)
eta = a_true[j] * (theta_true[:, None] - b_true[j][None, :])
cum_p = 1 / (1 + np.exp(-eta))
probs = np.concatenate([
1 - cum_p[:, :1],
cum_p[:, :-1] - cum_p[:, 1:],
cum_p[:, -1:],
], axis=1) # (N, K_j)
u = rng.uniform(size=(N, 1))
Y[:, j] = (u > np.cumsum(probs, axis=1)).sum(axis=1)
print(f"Response matrix shape: {Y.shape}")
for k in np.unique(K_per_item):
items_k = np.where(K_per_item == k)[0]
counts = np.bincount(Y[:, items_k].ravel(), minlength=k)
print(f"K={k}: {len(items_k)} items, category counts = {counts}")
Response matrix shape: (100, 20)
K=3: 7 items, category counts = [275 154 271]
K=4: 7 items, category counts = [256 85 113 246]
K=5: 6 items, category counts = [193 38 92 124 153]
df = pd.DataFrame(Y,
index=[f"user_{i+1}" for i in range(Y.shape[0])],
columns=[f"item_{j+1}" for j in range(Y.shape[1])])
df.tail()
| item_1 | item_2 | item_3 | item_4 | item_5 | item_6 | item_7 | item_8 | item_9 | item_10 | item_11 | item_12 | item_13 | item_14 | item_15 | item_16 | item_17 | item_18 | item_19 | item_20 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| user_96 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 2 | 3 | 3 | 0 | 0 | 0 | 4 | 0 | 3 |
| user_97 | 2 | 0 | 0 | 1 | 0 | 2 | 0 | 1 | 0 | 0 | 2 | 0 | 0 | 3 | 2 | 0 | 0 | 1 | 0 | 0 |
| user_98 | 2 | 0 | 0 | 0 | 0 | 2 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 3 | 0 | 1 | 2 | 0 | 0 | 4 |
| user_99 | 0 | 1 | 0 | 1 | 0 | 1 | 1 | 3 | 0 | 3 | 2 | 2 | 2 | 3 | 3 | 0 | 2 | 4 | 3 | 4 |
| user_100 | 0 | 1 | 0 | 1 | 0 | 2 | 0 | 3 | 0 | 0 | 0 | 0 | 0 | 0 | 2 | 3 | 2 | 0 | 0 | 4 |
# 縦持ちへ変換
user_categories = df.index
item_categories = df.columns
df_long = pd.melt(
df.reset_index(),
id_vars="index",
var_name="item",
value_name="response",
).rename(columns={"index": "user"})
df_long["user"] = pd.Categorical(df_long["user"], categories=user_categories, ordered=True)
df_long["item"] = pd.Categorical(df_long["item"], categories=item_categories, ordered=True)
df_long.head()
| user | item | response | |
|---|---|---|---|
| 0 | user_1 | item_1 | 2 |
| 1 | user_2 | item_1 | 0 |
| 2 | user_3 | item_1 | 2 |
| 3 | user_4 | item_1 | 2 |
| 4 | user_5 | item_1 | 0 |
import numpy as np
import pymc as pm
# indexと値の取得
user_idx = df_long["user"].cat.codes.to_numpy()
users = df_long["user"].cat.categories.to_numpy()
item_idx = df_long["item"].cat.codes.to_numpy()
items = df_long["item"].cat.categories.to_numpy()
responses = df_long["response"].to_numpy().astype("int64") # 0..K-1
# カテゴリ数
K = int(responses.max() + 1)
n_thresholds = K - 1
coords = {
"user": users,
"item": items,
"threshold": np.arange(n_thresholds),
"obs_id": np.arange(len(df_long)),
}
with pm.Model(coords=coords) as model:
responses_ = pm.Data("responses", responses, dims="obs_id")
theta = pm.Normal("theta", 0.0, 1.0, dims="user")
a = pm.LogNormal("a", 0.0, 0.5, dims="item")
# --- GRM の閾値:各 item ごとに (K-1) 本 ---
# ordered transform が last axis に対して単調増加を強制する想定
b = pm.Normal(
"b",
mu=np.linspace(-1, 1, n_thresholds), # 初期の目安
sigma=2.0,
dims=("item", "threshold"),
transform=pm.distributions.transforms.ordered,
)
# 線形予測子
eta = a[item_idx] * theta[user_idx]
# GRM の cutpoints: a_j * b_{jk}
# OrderedLogistic は P(Y >= k) = sigma(eta - cutpoints_k) を計算するため、
# Samejima のパラメタリゼーション P(Y >= k) = sigma(a*(theta - b)) に合わせるには
# cutpoints = a * b とする必要がある(a > 0 なので順序は保たれる)
cutpoints = a[:, None] * b
# 観測:item ごとの cutpoints を観測ごとに参照
pm.OrderedLogistic(
"obs",
eta=eta,
cutpoints=cutpoints[item_idx],
observed=responses_,
dims="obs_id",
)
モデル#
荘島宏二郎 & 豊田秀樹 (2004) を参考に、複数のモデルの尤度を掛けるようにして混合形式のモデルを構築する。
ある項目\(j\)のカテゴリ数が\(k\)個だとし、それをGRMでモデリングした項目特性曲線を \(P^{GRM(k)}_j(\theta)\) とすると、今回のデータはカテゴリ数が\(k=3\)の項目が7個、\(k=4\)の項目が7個、\(k=5\)の項目が6個なので
となる。同じカテゴリ数の項目ごとにグルーピングして実装すれば
with pm.Model() as model:
for k in [3, 4, 5]:
subset = data[K_per_item == k] # 対応する項目を取り出す
pm.OrderedLogistic(...) # GRMを構築
...
のように実装できる
K_per_item = df.max() + 1
unique_K = np.sort(np.unique(K_per_item))
with pm.Model() as model:
# theta, aはkによらず共通
theta = pm.Normal("theta", mu=0.0, sigma=1.0, shape=N)
a = pm.LogNormal("a", mu=0.0, sigma=0.5, shape=J)
# カテゴリ数Kが同じ項目ごとにまとめてGRMを構築
for k in unique_K:
item_idx = np.where(K_per_item == k)[0]
J_k = len(item_idx)
Y_k = Y[:, item_idx] # (N, J_k)
b_k = pm.Normal(
f"b_{k}",
mu=0.0,
sigma=1.5,
shape=(J_k, k - 1),
transform=pm.distributions.transforms.ordered,
initval=np.tile(np.linspace(-1.0, 1.0, k - 1), (J_k, 1)),
)
eta_k = pm.Deterministic(f"eta_{k}",theta[:, None] * a[item_idx][None, :]) # (N, J_k)
cutpoints_k = pm.Deterministic(f"cutpoints_{k}", a[item_idx][:, None] * b_k) # (J_k, K-1)
pm.OrderedLogistic(
f"y_{k}",
eta=eta_k,
cutpoints=cutpoints_k,
observed=Y_k,
)
pm.model_to_graphviz(model)

with model:
idata = pm.sample(
draws=3000,
tune=2000,
chains=4,
target_accept=0.9,
random_seed=42,
progressbar=True,
nuts_sampler="numpyro",
)
WARNING:2026-04-29 20:37:55,403:jax._src.xla_bridge:794: An NVIDIA GPU may be present on this machine, but a CUDA-enabled jaxlib is not installed. Falling back to cpu.
EAP推定値#
item_params = pd.DataFrame({"item": df.columns})
item_params["a"] = idata.posterior["a"].mean(dim=["chain", "draw"]).values # (J,)
for k in K_per_item.unique():
b_col = f"b_{k}"
B_k = idata.posterior[b_col].mean(dim=["chain", "draw"]).values
J_k = B_k.shape[1]
B_df = pd.DataFrame(B_k, columns=[f"b{i+1}" for i in range(J_k)])
for col in B_df.columns:
item_params.loc[np.array(k == K_per_item), col] = B_df[col].values
# mirtパッケージのような表
item_params
| item | a | b1 | b2 | b3 | b4 | |
|---|---|---|---|---|---|---|
| 0 | item_1 | 0.489036 | -0.561038 | 0.347300 | NaN | NaN |
| 1 | item_2 | 1.996779 | 0.126741 | 1.518604 | NaN | NaN |
| 2 | item_3 | 0.644764 | 0.497665 | 0.870190 | NaN | NaN |
| 3 | item_4 | 1.092062 | -1.700215 | 2.220444 | NaN | NaN |
| 4 | item_5 | 0.851446 | -1.085440 | -0.830939 | NaN | NaN |
| 5 | item_6 | 0.634875 | -1.676081 | -0.222854 | NaN | NaN |
| 6 | item_7 | 0.666209 | -0.536491 | 0.720370 | NaN | NaN |
| 7 | item_8 | 0.932530 | -1.359590 | -0.638903 | 0.599335 | NaN |
| 8 | item_9 | 1.832579 | 0.628938 | 1.822901 | 2.857112 | NaN |
| 9 | item_10 | 0.436971 | -1.925663 | -0.699537 | 0.517263 | NaN |
| 10 | item_11 | 0.940934 | -1.116973 | -0.544383 | 1.034707 | NaN |
| 11 | item_12 | 0.830151 | -0.968405 | -0.259681 | 1.653884 | NaN |
| 12 | item_13 | 0.445196 | -1.087842 | -0.387065 | 0.290356 | NaN |
| 13 | item_14 | 0.468102 | -1.913398 | -0.455333 | 0.074721 | NaN |
| 14 | item_15 | 0.823297 | -0.462799 | 0.134753 | 1.090493 | 1.951486 |
| 15 | item_16 | 0.768977 | -1.459521 | -1.174272 | -0.788920 | 2.241960 |
| 16 | item_17 | 0.940680 | -1.607840 | -1.466008 | 0.932928 | 1.214162 |
| 17 | item_18 | 0.635062 | -1.132506 | 0.061923 | 0.270567 | 1.003326 |
| 18 | item_19 | 2.166546 | -1.499126 | -1.306246 | -0.265567 | 0.632866 |
| 19 | item_20 | 0.601235 | -0.057220 | 0.431428 | 0.503008 | 2.731121 |
theta_mean = idata.posterior["theta"].mean(dim=["chain", "draw"]).values # (N,)
thetas = pd.DataFrame({"person": np.arange(N), "theta": theta_mean})
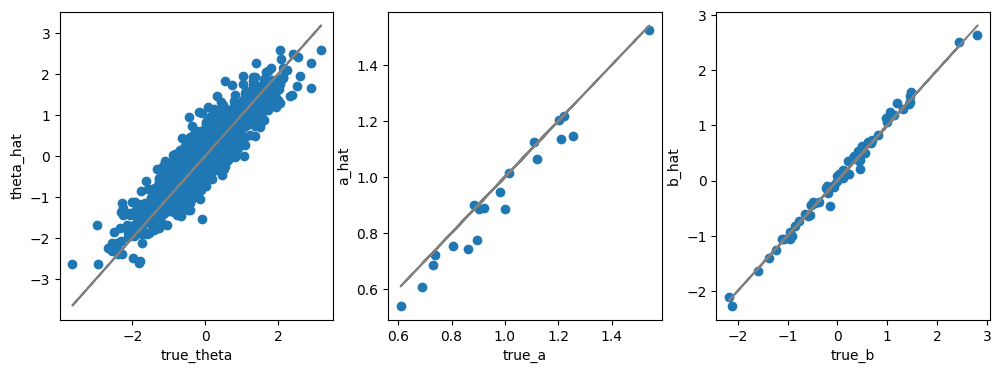
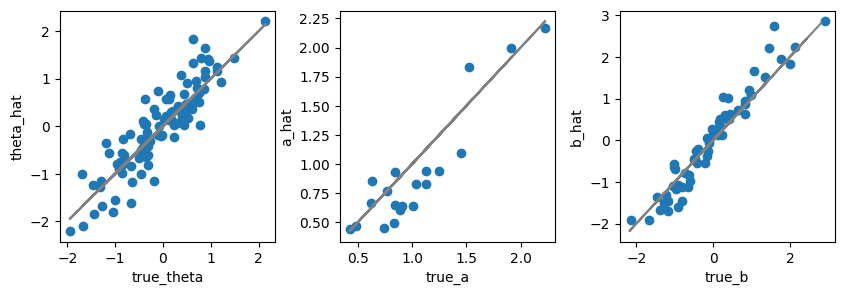
真値と比較#
分析手順#
チュートリアル論文 Zein, R. A., & Akhtar, H. (2025). Getting started with the graded response model: an introduction and tutorial in R によると
参考文献#
Lipovetsky, S. (2021). Handbook of Item Response Theory, Volume 1, Models. Technometrics, 63(3), 428-431.