PyMCでのIRTモデルの実装例#
既製品の標準的なモデル(2PLMなど)はパッケージで最尤推定すれば十分だが、Pythonの場合はIRT用のパッケージ(例えば pyirt)が数年前に更新が止まっている。
複雑な、独自のモデルはベイズモデリングする必要があり、PyMCやPyStanなどが候補になる。
2PLM#
データの生成#
| question_1 | question_2 | question_3 | question_4 | question_5 | question_6 | question_7 | question_8 | question_9 | question_10 | ... | question_16 | question_17 | question_18 | question_19 | question_20 | question_21 | question_22 | question_23 | question_24 | question_25 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| user_1 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | ... | 0 | 1 | 0 | 1 | 0 | 0 | 1 | 1 | 0 | 0 |
| user_2 | 1 | 1 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | ... | 1 | 0 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
| user_3 | 0 | 1 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | 1 | ... | 1 | 0 | 0 | 1 | 0 | 0 | 1 | 1 | 1 | 0 |
| user_4 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | ... | 1 | 1 | 0 | 1 | 0 | 0 | 1 | 1 | 1 | 1 |
| user_5 | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 1 | ... | 0 | 0 | 0 | 1 | 0 | 0 | 1 | 1 | 0 | 1 |
5 rows × 25 columns
| question_1 | question_2 | question_3 | question_4 | question_5 | question_6 | question_7 | question_8 | question_9 | question_10 | question_11 | question_12 | question_13 | question_14 | question_15 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| user_1 | 0 | 1 | 1 | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 1 | 0 |
| user_2 | 1 | 0 | 1 | 1 | 1 | 1 | 1 | 0 | 1 | 0 | 1 | 0 | 1 | 0 | 1 |
| user_3 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 |
| user_4 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| user_5 | 1 | 1 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 0 | 1 |
import matplotlib.pyplot as plt
import seaborn as sns
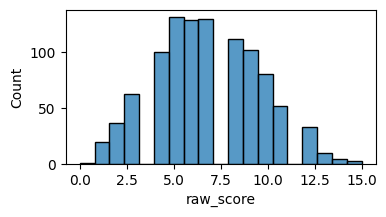
df["raw_score"] = df.sum(axis=1)
fig, ax = plt.subplots(figsize=[4,2])
sns.histplot(data=df, x="raw_score", ax=ax)
<Axes: xlabel='raw_score', ylabel='Count'>
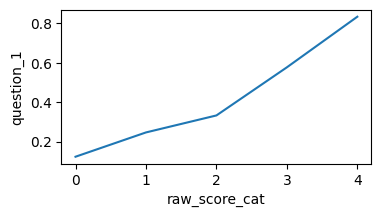
df["raw_score_cat"] = pd.qcut(df["raw_score"], q=5)
item_col = "question_1"
d = df.groupby("raw_score_cat")[item_col].mean().reset_index()
d["raw_score_cat"] = d["raw_score_cat"].cat.codes
fig, ax = plt.subplots(figsize=[4,2])
sns.lineplot(x="raw_score_cat", y=item_col, data=d, ax=ax)
del df["raw_score"]
del df["raw_score_cat"]
/tmp/ipykernel_22305/1755574120.py:4: FutureWarning: The default of observed=False is deprecated and will be changed to True in a future version of pandas. Pass observed=False to retain current behavior or observed=True to adopt the future default and silence this warning.
d = df.groupby("raw_score_cat")[item_col].mean().reset_index()
# 縦持ちへ変換
df_long = pd.melt(
df.reset_index(),
id_vars="index",
var_name="item",
value_name="response",
).rename(columns={"index": "user"})
df_long.head()
| user | item | response | |
|---|---|---|---|
| 0 | user_1 | question_1 | 0 |
| 1 | user_2 | question_1 | 1 |
| 2 | user_3 | question_1 | 0 |
| 3 | user_4 | question_1 | 0 |
| 4 | user_5 | question_1 | 1 |
モデルの定義#
注意点として、\(a\)に非負制約をかけないとMCMCが収束しにくい(\(\theta-b\)の値と\(a\)の値次第で同値の尤度が出てきて一意に決まらないので)
pm.LogNormal(mu=0.0, sigma=np.sqrt(0.5)) や pm.HalfNormal などが使われる事が多い様子
# indexと値の取得
user_idx, users = pd.factorize(df_long["user"])
item_idx, items = pd.factorize(df_long["item"])
responses = df_long["response"].to_numpy()
import pymc as pm
coords = {"user": df.index, "item": df.columns}
model = pm.Model(coords=coords)
with model:
# 観測値の配列
response_obs = pm.Data("responses", responses)
# 2PLM
a = pm.LogNormal("a", mu=0.0, sigma=np.sqrt(0.5), dims="item")
# a = pm.HalfNormal("a", sigma=0.5, dims="item")
b = pm.Normal("b", mu=0.0, sigma=1.0, dims="item")
theta = pm.Normal("theta", mu=0.0, sigma=1.0, dims="user")
obs = pm.Bernoulli("obs", p=pm.math.sigmoid(a[item_idx] * (theta[user_idx] - b[item_idx])), observed=response_obs)
g = pm.model_to_graphviz(model)
g

推定#
%%time
with model:
idata = pm.sample(random_seed=0, draws=1000)
Initializing NUTS using jitter+adapt_diag...
Multiprocess sampling (4 chains in 4 jobs)
NUTS: [a, b, theta]
Sampling 4 chains for 1_000 tune and 1_000 draw iterations (4_000 + 4_000 draws total) took 22 seconds.
CPU times: user 5.51 s, sys: 255 ms, total: 5.77 s
Wall time: 26 s
EAP推定量#
post_mean = idata.posterior.mean(dim=["chain", "draw"])
# 項目パラメータのEAP推定量
params_EAP = pd.DataFrame({
"item": coords["item"],
"a": post_mean["a"],
"b": post_mean["b"],
})
params_EAP.head()
| item | a | b | |
|---|---|---|---|
| 0 | question_1 | 1.188717 | 0.394483 |
| 1 | question_2 | 0.635774 | 1.941949 |
| 2 | question_3 | 0.918577 | -0.091389 |
| 3 | question_4 | 1.037007 | 0.334181 |
| 4 | question_5 | 1.013821 | -0.945100 |
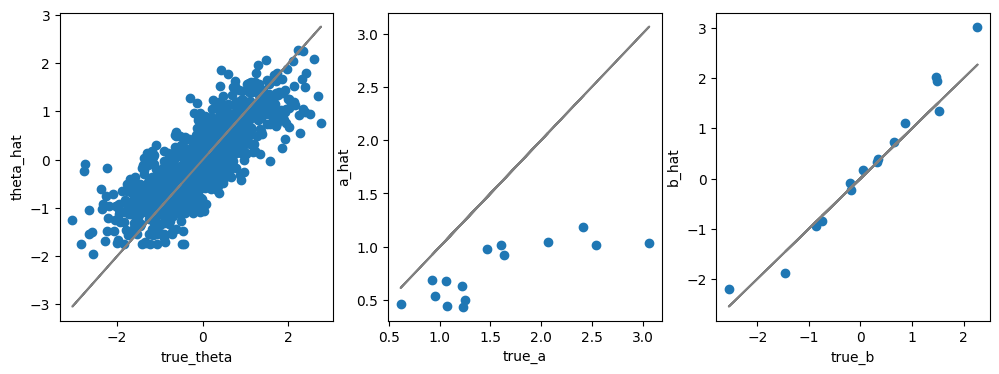
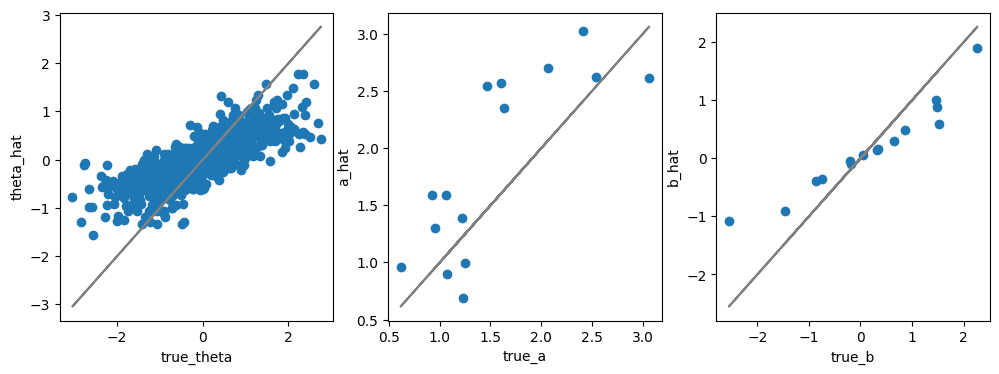
fig, axes = plt.subplots(figsize=[12,4], ncols=3)
ax = axes[0]
ax.scatter(true_thetas, post_mean["theta"])
ax.plot(true_thetas, true_thetas, color="gray")
_ = ax.set(xlabel="true_theta", ylabel="theta_hat")
ax = axes[1]
ax.plot(true_params[["a"]], true_params[["a"]], color="gray")
ax.scatter(true_params[["a"]], post_mean["a"])
_ = ax.set(xlabel="true_a", ylabel="a_hat")
ax = axes[2]
ax.plot(true_params[["b"]], true_params[["b"]], color="gray")
ax.scatter(true_params[["b"]], post_mean["b"])
_ = ax.set(xlabel="true_b", ylabel="b_hat")
MAP推定量#
with model:
map_est = pm.find_MAP()
fig, axes = plt.subplots(figsize=[12,4], ncols=3)
ax = axes[0]
ax.scatter(true_thetas, map_est["theta"])
ax.plot(true_thetas, true_thetas, color="gray")
_ = ax.set(xlabel="true_theta", ylabel="theta_hat")
ax = axes[1]
ax.plot(true_params[["a"]], true_params[["a"]], color="gray")
ax.scatter(true_params[["a"]], map_est["a"])
_ = ax.set(xlabel="true_a", ylabel="a_hat")
ax = axes[2]
ax.plot(true_params[["b"]], true_params[["b"]], color="gray")
ax.scatter(true_params[["b"]], map_est["b"])
_ = ax.set(xlabel="true_b", ylabel="b_hat")
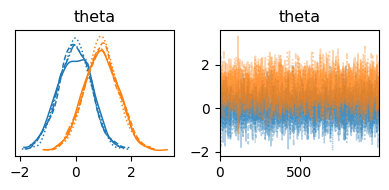
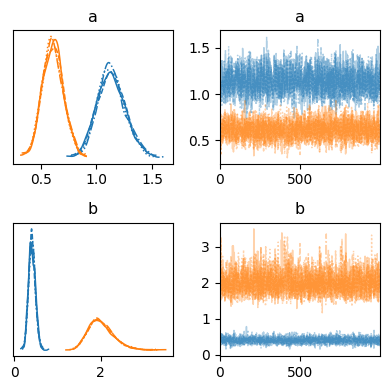
事後分布#
一部の項目の\(a_j, b_j\)
一部の回答者の\(\theta_i\)